bringing back power assert with Expecty
Last week I wrote about using source dependencies with sbt-sriracha for testing purpose. This week we’ll look into using Expecty to do power assert.
Power assert (or power assertion) is a variant of assert(...) function that that prints out detailed error message automatically. It was originally implemented by Peter Niederwieser (@pniederw) for Spock, and in 2009 it was merged into Groovy 1.7. Power assert has spread to Ruby, JavaScript, Rust, etc.
traditional assert statements
Let’s say you have something like a * b. Using a traditional assert, we would write:
hot source dependencies using sbt-sriracha
Source dependencies is one of features that existed in sbt since ever, but hasn’t been documented well.
immutable source dependency
Here’s how to declare source dependency to the latest commit for scopt commandline option parsing library.
lazy val scoptJVMRef = ProjectRef(uri("git://github.com/scopt/scopt.git#c744bc48393e21092795059aa925fe50729fe62b"), "scoptJVM")
ThisBuild / organization := "com.example"
ThisBuild / scalaVersion := "2.12.2"
lazy val root = (project in file("."))
.dependsOn(scoptJVMRef)
.settings(
name := "Hello world"
)
When you start sbt and run compile, sbt will automatically clone scopt/scopt under the staging directory, and link the builds together.
detecting Java version from Bash
Yesterday I wrote about cross JVM testing using Travis CI.
testing Scala apps on macOS using Travis CI
Here’s how we can test Scala apps on macOS using Travis CI. This is adapted from Lars and Muuki’s method: Testing Scala programs with Travis CI on OS X
dist: trusty
language: scala
matrix:
include:
## build using JDK 8, test using JDK 8
- script:
- sbt universal:packageBin
- cd citest && ./test.sh
jdk: oraclejdk8
## build using JDK 8, test using JDK 8, on macOS
- script:
- sbt universal:packageBin
- cd citest && ./test.sh
## https://github.com/travis-ci/travis-ci/issues/2316
language: java
os: osx
osx_image: xcode9.2
## build using JDK 8, test using JDK 9
- script:
- sbt universal:packageBin
- jdk_switcher use oraclejdk9
- cd citest && ./test.sh
jdk: oraclejdk8
## build using JDK 8, test using JDK 10
- script:
- sbt universal:packageBin
- citest/install-jdk10.sh
- cd citest && ./test.sh
jdk: oraclejdk8
scala:
- 2.10.7
before_install:
# https://github.com/travis-ci/travis-ci/issues/8408
- unset _JAVA_OPTIONS
- if [[ "$TRAVIS_OS_NAME" = "osx" ]]; then
brew update;
brew install sbt;
fi
cache:
directories:
- $HOME/.ivy2/cache
- $HOME/.sbt/boot
before_cache:
- find $HOME/.ivy2 -name "ivydata-*.properties" -delete
- find $HOME/.sbt -name "*.lock" -delete
Normally you’d write jdk: oraclejdk8 at the top level, but since the macOS image does not have the jdk_switcher script travis/travis#2317, we need to add to all entries in the matrix except for the osx one.
cross JVM testing using Travis CI
Oracle is moving to ship non-LTS JDK every 6 months, and LTS JDK every 3 years. Also it’s converging to OpenJDK. In this scheme, JDK 9 will be EOL in March 2018; JDK 10 will come out in March 2018, and EOL in September 2018; and LTS JDK 11 that replaces JDK 8 in September 2018 will stay with us until 2021.
As we will see quick succession of JDKs in the upcoming months, here’s a how-to on testing your app on JDK 8, JDK 9, and JDK 10 Early Access using Travis CI.
removing commas with sbt-nocomma
August, 2016
During the SIP-27 trailing commas discussion, one of the thoughts that came to my mind was unifiying some of the commas with semicolons, and take advantage of the semicolon inference.

This doesn’t actually work. @Ichoran kindly pointed out an example:
Seq(
a
b
c
)
This is interpreted to be Seq(a.b(c)) in Scala today.
sbt-sticker
As tweeted, I made some sbt stickers.

herding cats: day 17
Wrote herding cats: day 17 featuring initial and terminal objects, product, duality, and coproduct.
Coursera machine learning memo
This holiday break, I somehow got into binge watching Coursera’s Stanford Machine Learning course taught by Andrew Ng. I remember machine learning to be really math heavy, but I found this one more accessible.
Here are some notes for my own use. (I am removing all the fun examples, and making it dry, so if you’re interested in machine learning, you should check out the course or its official notes.)
Intro
Machine learning splits into supervised learning and unsupervised learning.
sbt server with Neovim
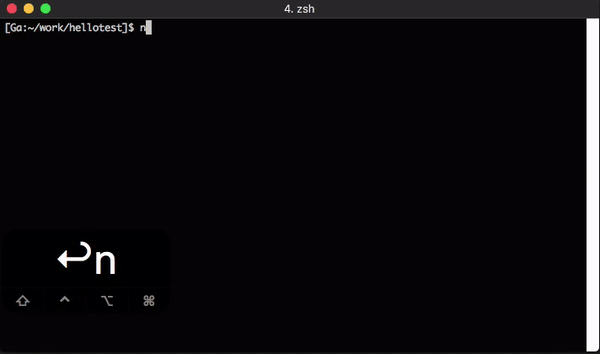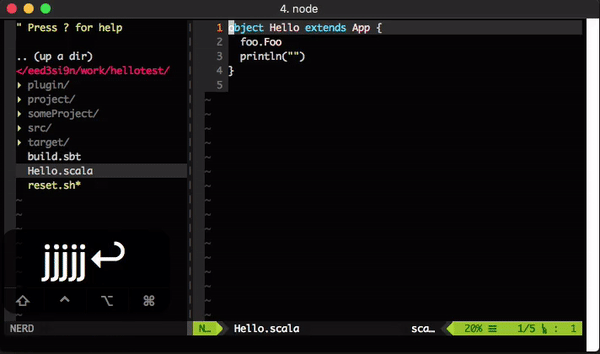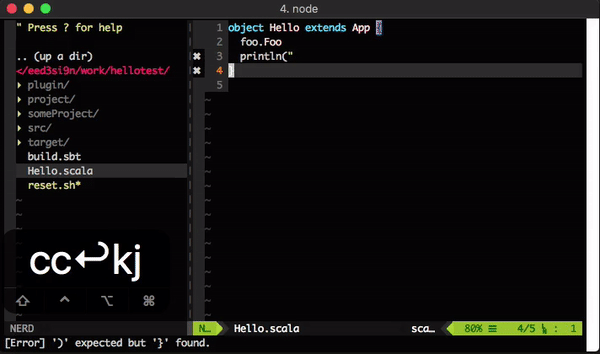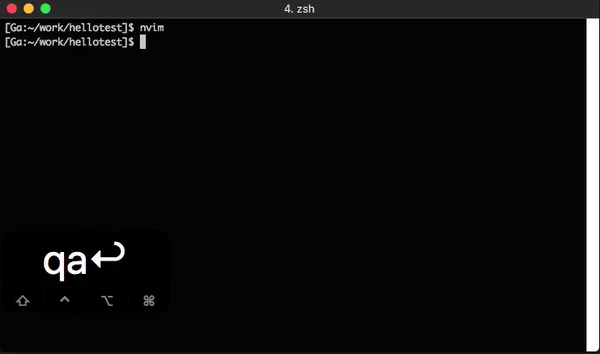
encoding file path as URI reference
In this post I am going to discuss an old new problem of encoding file path as Uniform Resource Identifier (URI) reference.
As of 2017, the authoritative source of information is RFC 8089 - The “file” URI Scheme written by Matthew Kerwin.
RFC 8089 The "file" URI Scheme https://tools.ietf.org/html/rfc8089 Wow, it actually happened.
— Matthew Kerwin (@phluid61) February 18, 2017
Future readers might also want to search for “file URI scheme RFC”, and find the latest version. If you’re a programmer, read the RFC. This post is to raise the awareness of the some of the issues around file to URI encoding, but it’s not a substitution.
sbt server with Sublime Text 3
On Tech Hub blog I demonstrated how to use sbt server from VS Code to display compiler errors from a running sbt session. In this post, I’ll show how to do that for Sublime Text 3 in this post.
setting up Sublime Text 3 with sbt server
First, add tomv564/LSP plugin to Sublime Text 3.
cd ~/Library/Application\ Support/Sublime\ Text\ 3/Packagesgit clone https://github.com/tomv564/LSP.git- Run ‘Preferences > Package Control > Satisfy Dependencies’
Next, download sbt-server-stdio.js and save it to ~/bin/ or somewhere you keep scripts. sbt server by default uses Unix domain sockets on POSIX systems and named pipe on Windows, but editors seem to expect stdio. The script is a Node script that’s included as our VS Code extension that discovers the socket, and fronts it with stdio.
Ergodox
Over the weekend I assembled an Ergodox.
- Infinity ErgoDox Ergonomic Keyboard Kit via massdrop
- Cherry MX Brown switches
- Datamancer Infinity Ergodox Hardwood Case (Black Walnut / Original) via massdrop
- Plum Blossom PBT Dye-Subbed Keycap Set (OEM, Blank) via massdrop

Scala language server using sbt
It’s been a month since sbt 1.0 shipped, and I can finally sit back and think about sbt server again. Using my weekends time, I started hacking on an implementation of Scala language server on top of sbt server.
what is a language server?
A language server is a program that can provide language service to editors like Visual Studio Code, Eclipse Che, and Sublime Text 3 via Language Server Protocol. A typical operation might be textDocument/didOpen, which tells the server that a source file was opened in the editor.
Persistent Versioning
In this post, I’d like to introduce a version scheme that I call Persistent Versioning. Most of the ideas presented in this post are not new or my own. Let me know if there’s already a name for it.
In 2015, Jake Wharton (@JakeWharton) wrote a blog post titled Java Interoperability Policy for Major Version Updates:
A new policy from @jessewilson and I for the libraries we work on to ensure major version updates are interoperable: https://t.co/zKqYRwrXmq
auto publish (a website) from Travis-CI
GitHub Pages is a convenient place to host OSS project docs. This post explains how to use Travis CI to deploy your docs automatically on a pull request merge.
1. Generate a fresh RSA key in some directory
Make a directory outside of your project first.
Pick a key name deploy_yourproject_rsa, so you can distinguish it from other keys.
$ mkdir keys
$ cd keys
$ ssh-keygen -t rsa -b 4096 -C "yours@example.com"
Generating public/private rsa key pair.
Enter file in which to save the key (/Users/xxx/.ssh/id_rsa): deploy_website_rsa
Enter passphrase (empty for no passphrase):
Keep the passphrase empty.
tray for Atreus
In the last post that I wrote about Atreus build, I noted that there’s an issue of keyboard positioning:
Even if I can overcome the layout and memorize the various symbol locations, there’s the issue of the placement. If I place the keyboard in between me and the laptop the screen becomes too far.
I solved this issue by making a tray for Atreus that I can position it on top of the MacBook Pro keyboard.
Atreus
Last night I finished making my Atreus keyboard from a DYI kit that I got a while back. Here are some of the details:
- I chose Matias Quiet Click switch option (gray slider). There’s no clicking.
- The modifiers use Matias Quiet Linear switches (red slider).
- There are 42 keys in split ortholinear layout.
- Mahogany ply case.
The materials
The kit comes with almost everything you need to assemble the Arteus keyboard. You need lacquer, a soldering iron, solder, and wire cutters.
Gigahorse 0.3.0
Gigahorse 0.3.0 is now released. See documentation on what it is.
OkHttp support
0.3.0 adds Square OkHttp support. Gigahorse-OkHttp is availble for Scala 2.10, 2.11, and 2.12.
According to the JavaDoc you actually don’t have to close the OkHttpClient instance.
scala> import gigahorse._, support.okhttp.Gigahorse
import gigahorse._
import support.okhttp.Gigahorse
scala> import scala.concurrent._, duration._
import scala.concurrent._
import duration._
scala> val http = Gigahorse.http(Gigahorse.config) // don't have to close
http: gigahorse.HttpClient = gigahorse.support.okhttp.OkhClient@23b48158
downloading and running app on the side with sbt-sidedish
I’ve been asked by a few people on downloading JARs, and then running them from an sbt plugin. Most recently, Shane Delmore (@shanedelmore) asked me about this at nescala in Brooklyn.
During an unconference session I hacked together a demo, and I continued some more after I came home.
sbt-sidedish
sbt-sidedish is a toolkit for plugin authors to download and run an app on the side from a plugin. It on its own does not define any plugins.
herding cats: day 16
Wrote herding cats day 16.
Contraband, an alternative to case class
Here are a few questions I’ve been thinking about:
- How should I express data or API?
- How should the data be represented in Java or Scala?
- How do I convert the data into wire formats such as JSON?
- How do I evolve the data without breaking binary compatibility?
limitation of case class
The sealed trait and case class is the idiomatic way to represent datatypes in Scala, but it’s impossible to add fields in binary compatible way. Take for example a simple case class Greeting, and see how it would expand into a class and a companion object:
Gigahorse 0.2.0
Gigahorse 0.2.0 is now released. The new change is that it abstracts over two backends. @alexdupre contributed migration from AHC 1.9 to AHC 2.0, which is based on Netty 4 in #12.
In addition, there’s now an experimental Akka HTTP support that I added. #15
Please see Gigahorse docs for the details.
gigahorse-github 0.1.0
gigahorse-github 0.1.0 is released. This is a Gigahorse plugin for Github API v3.
Gigahorse 0.1.0
Update: please use Gigahorse 0.1.1
Gigahorse 0.1.0 is now released. It is an HTTP client for Scala with Async Http Client underneath. Please see Gigahorse docs for the details. Here’s an example snippet to get the feel of the library.
scala> import gigahorse._
scala> import scala.concurrent._, duration._
scala> Gigahorse.withHttp(Gigahorse.config) { http =>
val r = Gigahorse.url("http://api.duckduckgo.com").get.
addQueryString(
"q" -> "1 + 1",
"format" -> "json"
)
val f = http.run(r, Gigahorse.asString andThen {_.take(60)})
Await.result(f, 120.seconds)
}
registry and reference pattern
There’s a “pattern” that I’ve been thinking about, which arises in some situation while persisting/serializing objects.
To motivate this, consider the following case class:
scala> case class User(name: String, parents: List[User])
defined class User
scala> val alice = User("Alice", Nil)
alice: User = User(Alice,List())
scala> val bob = User("Bob", alice :: Nil)
bob: User = User(Bob,List(User(Alice,List())))
scala> val charles = User("Charles", bob :: Nil)
charles: User = User(Charles,List(User(Bob,List(User(Alice,List())))))
scala> val users = List(alice, bob, charles)
users: List[User] = List(User(Alice,List()), User(Bob,List(User(Alice,List()))),
User(Charles,List(User(Bob,List(User(Alice,List()))))))
The important part is that it contains parents field, which contains a list of other users.
Now let’s say you want to turn users list of users into JSON.
sjson-new and the prisoner of Azkaban
This is part 3 on the topic of sjson-new. See also part 1 and part 2.
Within the sbt code base there are a few places where the persisted data is in the order of hundreds of megabytes that I suspect it becomes a performance bottleneck, especially on machines without an SSD drive. Naturally, my first instinct was to start reading up on the encoding of Google Protocol Buffers to implement my own custom binary format.
sjson-new and custom codecs using LList
Two months ago, I wrote about sjson-new. I was working on that again over the weekend, so here’s the update. In the earlier post, I’ve introduced the family tree of JSON libraries in Scala ecosystem, the notion of backend independent, typeclass based JSON codec library. I concluded that we need some easy way of defining a custom codec for it to be usable.
roll your own shapeless
In between the April post and the last weekend, there were flatMap(Oslo) 2016 and Scala Days New York 2016. Unfortunately I wasn’t able to attend flatMap, but I was able to catch Daniel Spiewak’s “Roll Your Own Shapeless” talk in New York. The full flatMap version is available on vimeo, so I recommend you check it out.
foundweekends
I made a new Github organization called foundweekends for people who like coding in the weekends. If you want to join, or have project ideas ping me on twitter or come talk to us on Gitter.
As the starter, it will pick up maintenance of conscript, giter8, and pamflet from @n8han.
sjson-new
background
One of the fun way of thinking about software projects is literary analysis. Instead of the actual source code, think of who wrote it when and why (what problem does it solve), and how it’s written (what influenced it). Within the Scala ecosystem, not too many genre are as rich as the JSON libraries.
In December 2008, the first edition of Programming in Scala came out, which used JSON as an example in the context of parser combinator, and showed that JSON parser can be written in 10 lines of code: