‘Ancillary Justice’ is written in a first-person narrative as the AI of thousands of years old starship Justice of Toren of The Radchaai Empire. Another interesting part is since the Radchaai language is genderless, the narrator constantly describes everyone as “she,” but later you might discover that some character might be he. There are other small details here and there that narrator might say, but you start to question it as the story develops. In other words, Ann Leckie has done a stylish job of show-and-not-tell about the world that she’s built.
As of Scala 2.13.0-M5, it’s planned that scala.Seq will change from scala.collection.Seq to scala.collection.immutable.Seq. Scala 2.13 collections rework explains a bit about why it’s been non-immutable historically. Between the lines, I think it’s saying that we should celebrate that scala.Seq will now be immutable out of the box.
Defaulting to immutable sequence would be good for apps and fresh code. The situation is a bit more complicated for library authors.
If you have a cross-built library, and
if your users are using your library from multiple Scala versions
and your users are using Array(...)
this change to immutable Seq could be a breaking change to your API.
We need to change the culture around tech conferences to improve the inclusion of women (and people from other backgrounds too!). For that, there needs to be clear signaling and communication about two basic issues
No, it’s not ok to hit on women at a conference.
Assume technical competence, and treat women as professional peers.
These points should be communicated over and over at each conference before the keynote takes place, and before socializing hours.
Red Mars is a science fiction classic written in 1992. This book is everything I wanted and more, starting with first hundred astronauts and cosmonauts migrating to Mars to build the infrastructure such that more people can migrate. By the middle of the book, thousands of people migrate to Mars. The book explores various dimensions the epic project, not just technological challenges, but psychological effects, personality differences, and political interests by superpowers. The geography of Mars is written in vivid, majestic details.
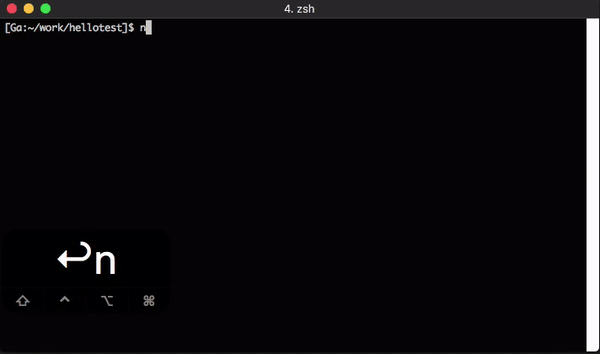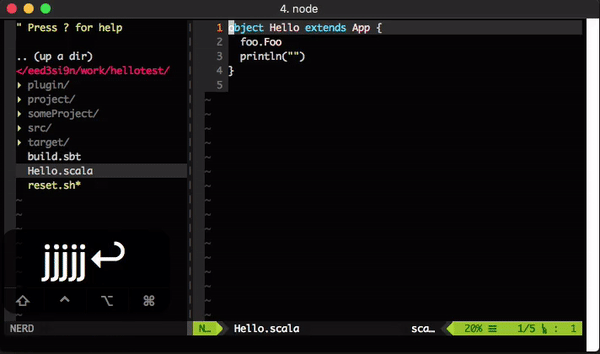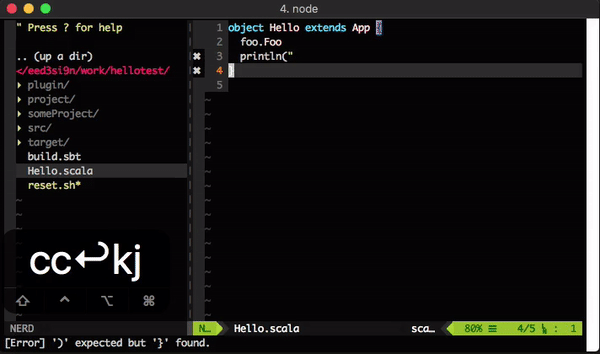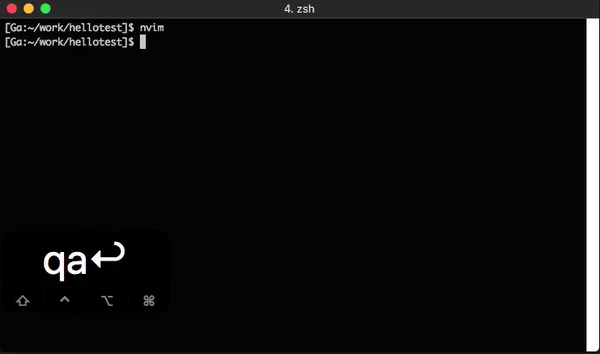
I’ve implemented “super shell” feature for sbt over the weekend. The idea is to take over the bottom n lines of the termnial, and display the current tasks in progress.
the limitation of using log as status report
Logs are useful in many situations, and sometimes it’s the only viable tool to find out what’s going on. But on a console app like sbt, using logs to tell the build user what’s going on doesn’t always work.
Compile, or compile not. There’s no warning. Two of my favorite Scala compiler flags lately are "-Xlint" and "-Xfatal-warnings".
Here is an example setting that can be used with subprojects:
ThisBuild/ organization :="com.example"ThisBuild/ version :="0.1.0-SNAPSHOT"ThisBuild/ scalaVersion :="2.12.6"lazyval commonSettings =List( scalacOptions ++=Seq("-encoding","utf8","-deprecation","-unchecked","-Xlint","-feature","-language:existentials","-language:experimental.macros","-language:higherKinds","-language:implicitConversions","-Ypartial-unification","-Yrangepos",), scalacOptions ++=(scalaVersion.value match{caseVersionNumber(Seq(2,12,_*),_,_)=>List("-Xfatal-warnings")case_=>Nil}),Compile/ console / scalacOptions --=Seq("-deprecation","-Xfatal-warnings","-Xlint"))lazyval foo =(project in file("foo")).settings( commonSettings, name :="foo",)
what’s -Xlint?
-Xlint enables a bunch of compiler warnings. @smogami contributed a page called Scala Compiler Options so we can now read what’s in -Xlint.
Working with GitHub and pull requests a lot, I end up accumulating stale branches that are no longer needed. In this post, we will look at how to clean the stale local branches.
There are mainly two strategies:
Pick a “master” branch, and delete what’s merged to it
Assuming branches are deleted first on GitHub, delete local branches that no longer exists on remote “origin”
I’ve been thinking about rich console applications, the kind of apps that can display things graphically, not just appending lines at the end. Here are some info, enough parts to be able to write Tetris.
ANSI X3.64 control sequences
To display some text at an arbitrary location on a termial screen, we first need to understand what a terminal actually is. In the middle of 1960s, companies started selling minicomputers such as PDP-8, and later PDP-11 and VAX-11. These were of a size of a refrigerator, purchased by “computer labs”, and ran operating systems like RT-11 and the original UNIX system that supported up many simultaneous users (12 ~ hundreds?). The users connected to a minicomputer using a physical terminal that looks like a monochrome screen and a keyboard. The classic terminal is VT100 that was introduced in 1978 by DEC.
Whether you want to try using OpenJDK 11-ea, GraalVM, Eclipse OpenJ9, or you are stuck needing to build using OpenJDK 6, jabba has got it all. jabba is a cross-platform Java version manager written by Stanley Shyiko (@shyiko).
AdoptOpenJDK 8 and 11
Here’s how we can use jabba on Travis CI to cross build using AdoptOpenJDK 8 and 11:
Power assert (or power assertion) is a variant of assert(...) function that that prints out detailed error message automatically. It was originally implemented by Peter Niederwieser (@pniederw) for Spock, and in 2009 it was merged into Groovy 1.7. Power assert has spread to Ruby, JavaScript, Rust, etc.
traditional assert statements
Let’s say you have something like a * b. Using a traditional assert, we would write:
dist: trustylanguage: scalamatrix:
include:
## build using JDK 8, test using JDK 8 - script:
- sbt universal:packageBin - cd citest && ./test.shjdk: oraclejdk8## build using JDK 8, test using JDK 8, on macOS - script:
- sbt universal:packageBin - cd citest && ./test.sh## https://github.com/travis-ci/travis-ci/issues/2316language: javaos: osxosx_image: xcode9.2## build using JDK 8, test using JDK 9 - script:
- sbt universal:packageBin - jdk_switcher use oraclejdk9 - cd citest && ./test.shjdk: oraclejdk8## build using JDK 8, test using JDK 10 - script:
- sbt universal:packageBin - citest/install-jdk10.sh - cd citest && ./test.shjdk: oraclejdk8scala:
- 2.10.7before_install:
# https://github.com/travis-ci/travis-ci/issues/8408 - unset _JAVA_OPTIONS - if [[ "$TRAVIS_OS_NAME" = "osx" ]]; thenbrew update;brew install sbt;ficache:
directories:
- $HOME/.ivy2/cache - $HOME/.sbt/bootbefore_cache:
- find $HOME/.ivy2 -name "ivydata-*.properties" -delete - find $HOME/.sbt -name "*.lock" -delete
Normally you’d write jdk: oraclejdk8 at the top level, but since the macOS image does not have the jdk_switcher script travis/travis#2317, we need to add to all entries in the matrix except for the osx one.
Oracle is moving to ship non-LTS JDK every 6 months, and LTS JDK every 3 years. Also it’s converging to OpenJDK. In this scheme, JDK 9 will be EOL in March 2018; JDK 10 will come out in March 2018, and EOL in September 2018; and LTS JDK 11 that replaces JDK 8 in September 2018 will stay with us until 2021.
As we will see quick succession of JDKs in the upcoming months, here’s a how-to on testing your app on JDK 8, JDK 9, and JDK 10 Early Access using Travis CI.
During the SIP-27 trailing commas discussion, one of the thoughts that came to my mind was unifiying some of the commas with semicolons, and take advantage of the semicolon inference.
This holiday break, I somehow got into binge watching Coursera’s Stanford Machine Learning course taught by Andrew Ng. I remember machine learning to be really math heavy, but I found this one more accessible.
Here are some notes for my own use. (I am removing all the fun examples, and making it dry, so if you’re interested in machine learning, you should check out the course or its official notes.)
Intro
Machine learning splits into supervised learning and unsupervised learning.
Future readers might also want to search for “file URI scheme RFC”, and find the latest version. If you’re a programmer, read the RFC. This post is to raise the awareness of the some of the issues around file to URI encoding, but it’s not a substitution.
On Tech Hub blog I demonstrated how to use sbt server from VS Code to display compiler errors from a running sbt session. In this post, I’ll show how to do that for Sublime Text 3 in this post.
cd ~/Library/Application\ Support/Sublime\ Text\ 3/Packages
git clone https://github.com/tomv564/LSP.git
Run ‘Preferences > Package Control > Satisfy Dependencies’
Next, download sbt-server-stdio.js and save it to ~/bin/ or somewhere you keep scripts. sbt server by default uses Unix domain sockets on POSIX systems and named pipe on Windows, but editors seem to expect stdio. The script is a Node script that’s included as our VS Code extension that discovers the socket, and fronts it with stdio.
It’s been a month since sbt 1.0 shipped, and I can finally sit back and think about sbt server again. Using my weekends time, I started hacking on an implementation of Scala language server on top of sbt server.
what is a language server?
A language server is a program that can provide language service to editors like Visual Studio Code, Eclipse Che, and Sublime Text 3 via Language Server Protocol. A typical operation might be textDocument/didOpen, which tells the server that a source file was opened in the editor.
In this post, I’d like to introduce a version scheme that I call Persistent Versioning. Most of the ideas presented in this post are not new or my own. Let me know if there’s already a name for it.
GitHub Pages is a convenient place to host OSS project docs.
This post explains how to use Travis CI to deploy your docs automatically on a pull request merge.
1. Generate a fresh RSA key in some directory
Make a directory outside of your project first.
Pick a key name deploy_yourproject_rsa, so you can distinguish it from other keys.
$ mkdir keys
$ cd keys
$ ssh-keygen -t rsa -b 4096 -C "yours@example.com"Generating public/private rsa key pair.
Enter file in which to save the key (/Users/xxx/.ssh/id_rsa): deploy_website_rsa
Enter passphrase (empty for no passphrase):
 Ancillary Justice by Ann Leckie
Ancillary Justice by Ann Leckie