2026-02-13
/ sbt
sbt という名の小さな村
僕は、有志で sbt と Zinc のメンテナをやっていて、それらは Scala という、マルチ・パラダイムかつ JVM、JS、ネイティブを対象とするマルチ・プラットフォームなプログラミング言語を駆動するツールチェインの一部を担っている。Scala 言語は 20年近く前からあるが、特に 2009年 に Twitter社が採用して以降、Apache Spark、LinkedIn、Morgan Stanley、ING、Airbnb、Spotify、Netflix、国内だとリクルート、ドワンゴ、サイバーエージェント社などで採用事例があった。
経年の Scala の名声とは一歩おいて、sbt も Zinc も依然としてニッチなプロジェクトで、基本的には僕個人と Scala Center との協力、そして一部 Scala ユーザと EFPL、Lightbend/Akka社、JetBrains社、VirtusLab社、Databricks社、Gradle社などのツール担当の人たちから形成される内輪の人たちが送ってくれるコントリビューションで開発が行われていて、だいたいポーランドとかスイスの Scala カンファレンスに顔を出しているとお互い面識ができてくる。
2025-10-12
/ scala
本稿では Scala 3 の差分コンパイルと、関連する問題についてみていく。Scala 2.12 と 2.13 の差分コンパイルはある程度安定していると思うが、僕の使っている感覚だと Scala 3 は壊れやすい気がする。この原因を調査して、修正案を scala/scala3#24171 として送ろうと思う。
2024-11-18
/ scala
本稿では、Hedgehog for Scala というプロパティー・ベース・テスト・フレームワークを簡単に紹介したい。Hedgehog for Scala は、Jacob Stanley さんと Nikos Baxevanis さん共著の Haskell Hedgehog というライブラリを基に 2018年ごろ Charles O’Farrell さんが実装したもので、最近では Kevin Lee さんが主にメンテナンスを行っている。
2024-09-28
/ sbt
本稿は sbt 2.x 開発に関する記事で、sbt 2.x リモートキャッシュ 、Bazel 互換な sbt 2.x リモートキャッシュ 、酢鶏、パート4 、パート5 などの続編だ。僕は個人の時間を使って Scala Center や EngFlow の Billy さんなどのボランティアの人と協力して sbt 2.x の作業をしていて、このような記事はプルリクコメントの拡張版で、将来 sbt に実装されるかもしれない機能を共有できたらいいと思っている。
sbt query
sbt 2.0 ideas で出したアイディアとして sbt query というものがある:
sbt query 参照。クエリはサブプロジェクトをふるい分けるのに使うことができる。
sbt-projectmatrix がデフォルトで使われるようになると、サブプロジェクトの数は増加することになる。大規模なコードベースで作業してる人は既に大量のサブプロジェクトを取り扱っているかもしれない。
sbt 2.0 でのタスク集約におけるサブプロジェクトのふるい分け機構をここで提案したい:
sbt .../test
sbt abc.../test
sbt ...@scalaBinaryVersion= 3/test
スラッシュ構文にこれを統合させるというアイディアはthe GitHub discussion において Adrien Piquerez さんが提案したものだ。
クエリ構文は何を行うか?
print コマンドと組み合わせた例だ:
sbt: root> print .../name
foo / name
foo
bar / name
bar
baz / name
baz
name
root
このとき ... は、全サブプロジェクトを意味し、sbt 1.x における print name と同義だ。次に、名前が b から始まるサブプロジェクトだけを表示してみる:
2024-09-08
/ sbt
本稿は sbt 2.x 開発に関する記事で、sudori part3 、sbt 2.x リモートキャッシュ 、Bazel 互換な sbt 2.x リモートキャッシュ 、酢鶏、パート4 などの続編だ。僕は個人の時間を使って Scala Center や EngFlow の Billy さんなどのボランティアの人と協力して sbt 2.x の作業をしていて、このような記事はプルリクコメントの拡張版で、将来 sbt に実装されるかもしれない機能を共有できたらいいと思っている。
導入
今週はコネチカット州の浜辺の町で遅い夏休みを取って地元のスケボースポットをチェックしたり、少し冷ためな海に入ったり、ロブスター・ロールを食べ比べたりしていた。スケボーをしたり海遊びの合間に sbt におけるテストのリモート・キャッシュの作業をしたり、関連する実験をしたりしていた。開発用の覚書として、ここに結果を報告したい。
酢鶏、パート4 では compile タスクのリモート・キャシュを見た。compile がキャッシュできれば役立つのは間違い無いが、CI (継続的統合) システムの多くの時間はコードのコンパイルではなくテストに割かれることが多いのではないだろうか。Bazel は数桁違いに高速な CI の性能を叩き出すことがあるが、その一つの理由としてデフォルトでの test コマンドがリモート・キャッシュ化されているということが挙げられる。言い換えると、Bazel を使った場合、もし CI マシン上でテストが一度実行されると、インプットが変わるまではそのテスト結果はキャッシュされ続ける。
sbt 上級者の読者の皆さんは、sbt には既にローカルで差分テストを行う testQuick があるじゃないかとお気づきかもしれない。testQuick の難点は、キャッシュの無効化にタイムスタンプを用いるため、ビルド的に非密閉 (non-hermetic) で、そのためマシン間で再現性が無いことだ。本稿では、マシン間で安全に共有できる sbt 2.x のテスト・キャッシュを考察する。対応するプルリクは sbt/sbt#7644 だ。
2024-08-18
/ sbt
本稿は sbt 2.x 開発に関する記事で、sudori part3 、sbt 2.x リモートキャッシュ 、Bazel 互換な sbt 2.x リモートキャッシュ などの続編だ。僕は個人の時間を使って Scala Center と強力して sbt 2.x の作業をしていて、このような記事はプルリクコメントの拡張版で、将来 sbt に実装されるかもしれない機能を共有できたらいいと思っている。
2024年8月現在での状況
2024年4月の段階から一応 Bazel 互換のリモートキャッシュ機能が入っている。この実装はキャッシュされた副作用としてファイル・アウトプットをサポートする。言い換えると、まっさらなマシンでビルドを行ったとしても、リモート・キャッシュが潤っていれば、コンパイラを実行する代わりに JAR をダウンロードできるという算段だ。
しかし、実際に差分コンパイルを行うにはディレクトリに任意の数のファイルを作ることをサポートする必要がある。頑張れば他の方法もあるのだが、今のところディレクトリをサポートするのが現実的な次のステップだと思う。
ファイル・ディレクトリ問題
ファイル・ディレクトリのキャッシュ化は sbt 2.x リモートキャッシュ で列挙した様々なキャッシュ関連の問題に当たることになる:
ファイル・ディレクトリは相対パス名、ディレクトリに関する一意な証明、ファイル・システム内の実際のディレクトリなど色々なものを指す可能性がある
実際のファイル・ディレクトリは任意の数のファイルを含む
恐らく、ディレクトリをキャッシュするのに大量のネットワーク呼び出しはしたくない
アウトプットの宣言
sbt/sbt#7621 において、Def.declaraOutputDirectory という新しいアウトプットを導入した:
Def . declareOutputDirectory( dir)
これはタスク内で呼び出すことをでディレクトリのアウトプットを宣言する。これは、タスクの返り値の型とは異なることに注意。例えば、compile タスクは Analysis を返すが、横で *.class ファイルを生成して、事前に取り決められたディレクトリを使って他のタスクはその内容を使うということが行われている。宣言することでこの流れがもう少し明示的になる。具体例だとこのようになる:
import sjsonnew.BasicJsonProtocol.given
lazy val someKey = taskKey[ Int ]( "" )
someKey : = ( Def . cachedTask {
val conv = fileConverter. value
val dir = target. value / "foo"
IO . write( dir / "bar.txt" , "1" )
val vf = conv. toVirtualFile( dir. toPath())
Def . declareOutputDirectory( vf)
1
}). value
NativeLink キャッシュの設定
[NativeLink][nativelink] は比較的新しいリモート実行バックエンドで、Rust で実装されており、高速であることにこだわっている。オープンソースだが、NativeLink Cloud というサービスも行っていて、無料でお試しできると友達の Adam Singer がよく言っている。
2024-07-20
/ scala
@ifdef は Scala コンパイラ・プラグインで、Scala 言語における条件付きコンパイルを実装する。ifdef 0.3.0 では Scala.JS と Scala Native のサポートを追加した。
Scala Version
JVM
JS (1.x)
Native (0.5.x)
3.x
✅
✅
✅
2.13.x
✅
✅
✅
2.12.x
✅
✅
✅
2024-06-24
/ scala
何で Scala 3 をそんなに推すのかと聞かれることがあるので、リスト形式で書き出してみた。順は特に無し。これは僕が Scala 3 をどう書いているかとか、将来どう書きたいのかみたいな個人的な好みに基づいているので、それは注意してほしい。
2024-04-05
/ sbt
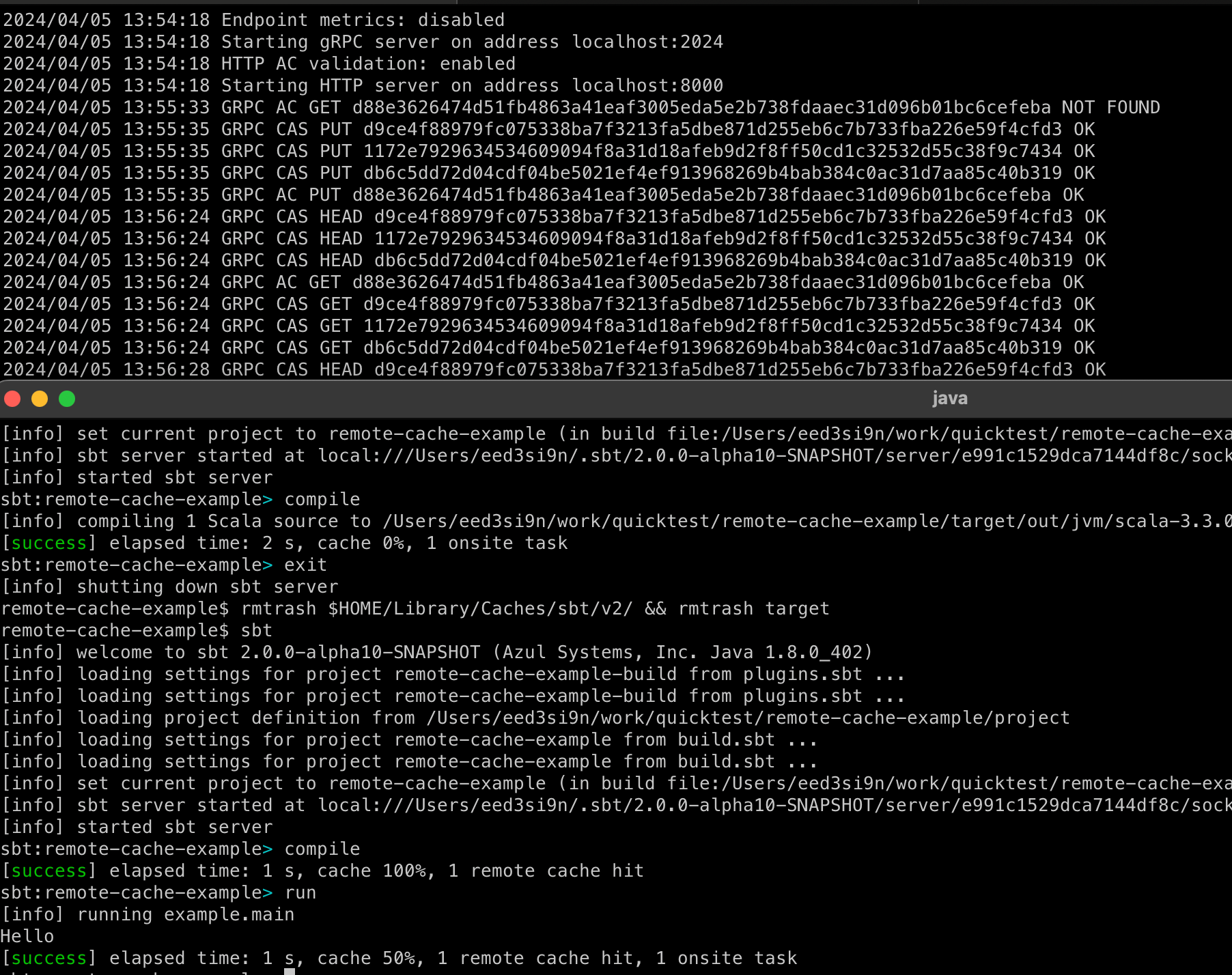
本稿は sbt 2.x リモートキャッシュ関連の第3部だ。ここ数年自分の時間を使って sbt 2.x の開発を行っていて、最近は Scala Center にも手伝ってもらっている。これらの記事はプルリクコメントの拡張版で将来 sbt に実装されるかもしれない機能を共有できたらいいと思っている。
約1年前 sbt 2.x における自動キャッシュ・タスクの設計の提案を RFC-1: sbt cache ideas で行い、「sbt 2.x リモートキャッシュ」 では実装の解説を行った:
someKey : = Def . cachedTask {
val output = StringVirtualFile1 ( "a.txt" , "foo" )
Def . declareOutput( output)
name. value + version. value + "!"
}
リモートキャッシュは、マシン間でビルドの結果を共有することで劇的な性能の改善を可能とする。2020年に、僕は sbt 1.x のコンパイルキャッシュ を実装した。これも compile タスクに限られていたが、有意な性能向上があることが何例も報告されている。最近だと、Leveraging sbt remote caching on a big modular monolith (2024) において、Teads 社の Sébastien Boulet さんが以下のように書いている:
完全キャッシュ・ヒットの場合は sbt ビルドは 3分30秒かかる。全てのタスクがキャッシュ化されているわけでは無いのでやはり数分かかってしまう。(中略) 一方、Scala Steward がプルリクを送ってライブラリが更新するなどして完全キャッシュ・ミスがあった場合は全てがリビルドされ、テストが実行される。これは 45分かかる。そのため、完全キャッシュ化されたビルドは 92% 効率化されていると言える。
実際に、エンジニアが経験するのはこの両極端の間のどこかに位置して、導入した変更に応じて著しくビルド時間の変化がある。
sbt 2.x のキャッシュに戻ると、これまでの所 compile タスクを例に汎用的な機構を作るための基盤を入れ替えることに集中してきたので、リモート・キャッシュと言えどまだ「分散」の部分には手を出していなかった。本稿ではこれを見ていく。
2023-12-21
これは Scala Advent Calendar 2023 の 23日目の記事です。21日目は、さっちゃんのpath 依存型って何? 調べてみました! でした。
はじめに
リモートキャッシュは、ビルドの結果を共有することで劇的な性能の改善を可能とする。Mokhov 2018 ではクラウド・ビルド・システム (cloud build system) とも呼ばれている。これは、僕が Blaze (現在は Bazel としてオープンソース化されている) のことを聞いて以来関心を持ち続けてきた機能だ。2020年に、僕は sbt 1.x のコンパイルキャッシュ を実装した。reibitto さんの報告によると「以前は全てをコンパイルするのに 7分かかっていたが、15秒 で終わるようになった」らしい。他にも 2x ~ 5x 速くなったという報告を他の人も行っている。これらは期待の持てる内容であることに間違いないが、現行の機能は少し不器用で compile タスクにしか使えないという限界がある。2023年の3月に、RFC-1: sbt cache ideas として現状の課題と対策の設計のアウトラインを書き出してみた。以下に課題をまとめる:
問題1: sbt 1.x は compile のリモートキャッシュ、およびその他いくつかのタスクに対してディスクキャッシュを実装するが、カスタムタスクが参加できるソリューションが望ましい。
問題2: sbt 1.x はディスクキャッシュとリモートキャッシュで別の機構を持つが、ビルドユーザがローカルかリモートのキャッシュかを切り替えられる統一した機構が望ましい。
問題3: sbt 1.x は Ivy resolver をキャッシュの抽象化に用いたが、よりオープンなリモートキャッシュ・バックエンドが望ましい
12月中は適当に自分でプロジェクトを選んで 毎日少しでもいいから作業して、それをブログに数行ずつ記録したり #decemberadventure というハッシュタグをつけて投稿するという独りアベントが Mastodon 界隈の一部で流行ってて、僕の december adventure 2023 として、sbt 2.x のリモートキャッシュに挑戦してみようと思った。実装の提案は GitHub #7464 で、本稿では、提案した変更点の解説を行う。注意 : sbt の内部構造に関する予備知識はあんまり必要としないが、プルリクコメントの拡張版のようなものなので上級レベルの読者を想定している。あと、プルリク段階なので書いている先から詳細はどんどん変わっていくかもしれない。
2023-07-15
/ bazel / scala
Scalafix について
コードベースが大型化するにつれ、自動リファクタリングを行うことができる言語ツールがあると便利だ。幸いなことに、2016年に Scala Center が Scalafix を作ってくれた。公開時のブログ記事 の中で Ólafur Geirsson さんは:
Scalafix は、簡単かもしれないが単調に繰り返されるコード変換を受け持つことで、あなたが意識を向ける価値のあることに集中することができます。大まかに説明すると、Scalafix はソースを読んで、非推奨機能の使用を新しい代替へと変換し、元のソースに書き込みます。
と解説していて、Scala 3 マイグレーションが動機になっていたことがうかがえる。
現在は、Scalafix は Brice Jaglin さんらによってメンテされていて、Scala 3 マイグレーション以外でも一般のリンティングやリファクタリングのツールとして使われている。例えば吉田さん (xuwei-k) なんかは数百の Scalafix を書いたらしく、その一部は xuwei-k/scalafix-rules にも公開されている。
Scalafix 独特の特徴として、syntactic (構文的) と semantic (意味論的) という2種類のルールがある。
syntactic rule は、コンパイルすることなくソースコードに対して直接実行することができる。シンプルだが、コード解析の力には制限がある。
semantic rule は、シンボルや型を用いてより高度なコード解析を行うことができるが、入力ソースを SemanticDB コンパイラ・プラグインと共にコンパイルしたものを事前に用意する必要がある。
syntactic rule は Scalafix CLI さえあれば良いので、Bazel との統合は特に必要無い。一方で、semantic rule は semanticdb などを渡して回るため、少し作業が必要となる。
Bazel 統合の先行研究
Bazel + Scalafix
手順の概要
2023-04-17
/ scalamatsuri
今週末、virtual/Tokyo ハイブリッドの ScalaMatsuri が開催された。まずは、登壇者の皆さん、スポンサー各社、参加者の皆さんにお礼します。
初のハイブリッドということで、至らない点も多々あったけども、成功したカンファレンスだったのではと思う。僕は、16名の ScalaMatsuri スタッフの一員、それからメインのセッションと飛びコンでの登壇者として参加させてもらった。
2023-02-20
/ bazel / scala
一般論として Bazel は、モノバージョンニングといって、(JUnit や Pandas など) どのライブラリでもモノリポ内の全てのターゲットが同一のバージョンを使うという形態を好む。
モノバージョニングは、モノリポ内で発生しうるバージョン衝突を劇的に減らすため、よりコード再利用性を改善させるという効果がある。
しかし、実際に運用してみると全社が二人三脚状態になるという欠点も出てくる。
例えばサービス A、B、C、D の全てが Big Framework 1.1 を使っていると、デグレ (regression) があるかもしれないので全てを同時に Big Framework 1.2 に移植するのは人的負荷が高かったりする。
そんなこんなで数年が経ち、Big Framework 2.0 がリリースされて、やっぱりこれも採用はリスキーなのではということになる。
Scala エコシステムでは、sbt を用いてライブラリ作者がライブラリを複数の Scala 標準ライブラリやその他のフレームワークに対してビルドするというのは普通に行われている。
これはクロスビルド と呼ばれている。(x86 から aarch64 など CPU アーキテクチャをまたいだコンパイルをクロスコンパイル と言ったりするがそれとは別なことに注意)
このクロスビルドという概念は、同ブランチ内で中長期に渡って色々な軸のマイグレーションを可能とすることから、Bazel においても有用なものじゃないかと思っている。
例えば現行のモノリポが Scala 2.12 だとして、徐々にマイグレーションを行ってほとんどのターゲットが Scala 2.12 と Scala 2.13 の両方でビルド可能な状態へ持っていく。
これは、一部のチームが全社に先行して新バージョンを試しつつ、コードベースとしては普通に進んでいくことができる。
local_repository ハック
先週、@ianoc さんに Bazel でクロスビルドを可能とする機構を教えてもらった。
僕たちがやったのは Python の外部ライブラリの切り替えだが、本稿では Scala のクロスビルドを実装する。
(思い出すと去年、Long Cao さんがバーに入る行列で待っている間にこの説明を試みてくれた気がするが、当時はこのテクニックが非常に強力なものだと僕がイマイチ理解できなかった。)
まず基本を先に言うと、ルートの WORKSPACE 内でサブディレクトリを参照する local_repository--override_repository
2022-12-22
2022-11-20
僕は Twitter社の Build/Bazel Migration チームでスタッフ・エンジニアとして勤務していた。信じられないような 2年の後、2022年11月17日をもって退職した (企業買収後のレイオフでも任意でもあんまり関係無いが、僕は任意退職希望のオファーを取った)。Twitter社は、切磋琢磨、多様性、そして Flock を構成する全ての人に対して溢れ出る優しさというかなり特別な文化を持った職場だった。これを間近で経験して、その一員となる機会を得たことに感謝している。(Flock は「鳥の群れ」の意で、社内での Twitter社の通称)
以下は過去2年の簡単な振り返りだ。尚本稿での情報は、既に公開されているトークやデータに基づいている。買収後、うちのチームだけでも 10名以上のメンバーが Twitter社を抜けたので、在籍・元含め LinkedIn プロファイルへのリンクを本稿各所に貼った。
2021-12-31
/ sbt
sbt、Bazel、その他多くのビルドツールにおいて、「テスト」という用語が多様なレベルにまたがることが多いため、
それを曖昧無く定義しておくことは特に事前、事後処理、並列処理などを考えるときに役に立つのではないかと思う。
先に書いてしまうと、テストには以下の 4つのレベルがある:
テスト・コマンド
テスト・モジュール
テスト・クラス
テスト・メソッドまたはテスト式
コマンドライン・インターフェイスとしてのテスト
最上位のレベルはビルド・ツールがユーザに test コマンドととして提供するものだ。
ユーザが sbt シェルに test と打ち込むか、ターミナルから sbt --client test と打ち込むと、sbt のコマンド・エンジンは「test」を集約リストに列挙されたサブプロジェクト内でのタスク実行へと持ち上げる。
例えば root サブプロジェクトが core と util というサブプロジェクトを集約する場合、test は root/Test/test、core/Test/test、util/Test/test の並列実行だと解釈される。
僕はこの振る舞いをコマンド・ブロードキャストと呼んでいる。
Bazel ではこのブロードキャストはより明示的にユーザによって行われる。
例えば、ユーザが bazel testl example/... と打ち込むと、Bazel は example1/ ディレクトリ以下の全てのテスト・ターゲットを再帰的にクエリして、発見されたテスト・ターゲットを並列的にテストする。
モジュールとしてのテスト
共通しているのは「コマンドとしてのテスト」がテストモジュールを集約して、それらを並列実行することだ。
sbt は典型的にテスト・モジュールをサブプロジェクトと Test コンフィグレーションのペアとして表す。
Bazel はテスト・モジュールを scala_test(...) のような何らかのターゲットとして表す。
Bazel は rules_scala の scala_test_suite(...) のような名前付きのテスト集約も提供する。
Bazel に関して少し補足しておくと、テスト・モジュールの処理は非常に優秀だということだ。
デフォルトでテストの結果はキャッシュされ、キャッシングはリモート・キャッシュへと設定することができ、
実行環境をリモート・マシンへと設定することもできる。
そのため、ラップトップ上から環境を整えれば何百ものジョブを起動することができる。
また、ターゲットは従来のビルドツールよりも細かく作られ、理論上 .scala ファイルごとに
scala_test(...) ターゲットを宣言して(別のマシンで)並列実行することができる。
クラスとしてのテスト
JUnit、MUnit、ScalaTest、Specs2、Hedgehog、Verify などの JVM テストフレームワークは関連するテスト・メソッドをクラスやオブジェクトを用いてグループ化する。
Scala では、これらのテスト・クラスが FunSuite のように「suite」と名付けられることがあるが、JUnit における Suite は
複数のテスト・クラスを集約する特殊なテスト・クラスを指す。
2021-09-17
/ scala
Ólaf さんの olafurpg/setup-scala を使ってプロジェクトを JDK 17 でテストする簡単な解説をしてみる。Setting up GitHub Actions with sbt でドキュメント化されている以下の設定をスタート地点とする。
name : CI
on :
pull_request :
push :
jobs :
test :
strategy :
fail-fast : false
matrix :
include :
- os : ubuntu-latest
java : 11
jobtype : 1
- os : ubuntu-latest
java : 11
jobtype : 2
- os : ubuntu-latest
java : 11
jobtype : 3
runs-on : ${{ matrix.os }}
steps :
- name : Checkout
uses : actions/checkout@v1
- name : Setup
uses : olafurpg/setup-scala@v13
with :
java-version : "adopt@1.${{ matrix.java }}"
- name : Build and test
run : |
case ${{ matrix.jobtype }} in
1)
sbt -v "mimaReportBinaryIssues; scalafmtCheckAll; +test;"
;;
2)
sbt -v "scripted actions/*"
;;
3)
sbt -v "dependency-management/*"
;;
*)
echo unknown jobtype
exit 1
esac
shell : bash
例えば、jobtype が 3 の場合は JDK 8 を使いたいとして、jobtype が 1 と 2 の場合は JDK 17 でテストしたいとする。sbt-ci-release は JDK を持ってくるのに jabba を使っているが、これを書いている時点では各社の openjdk 17.0 ディストロが jabba にまだ上がっていない。しかし、Eclipse Adoptium 旧名 AdoptOpenJDK からバイナリが出たのでカスタム JDK モードを利用して強引に使うことが可能だ:
2021-09-06
/ scala
はじめに
マクロ は楽しくかつ強力なツールだが、使いすぎは害もある。責任を持って適度にマクロを楽しんでほしい。
マクロとは何だろうか? よくある説明はマクロはコードを入力として受け取り、コードを出力するプログラムだとされる。それ自体は正しいが、map {...} のような高階関数や名前渡しパラメータのように一見コードのブロックを渡して回っている機能に親しんでいる Scala プログラマには「コードを入力として受け取る」の意味が一見分かりづらいかもしれない。
以下は、僕が Scala 3 にも移植した Expecty という assersion マクロの用例だ:
scala> import com.eed3si9n.expecty.Expecty.assert
import com.eed3si9n.expecty.Expecty.assert
scala> assert( person. say( word1, word2) == "pong pong" )
java. lang. AssertionError : assertion failed
assert( person. say( word1, word2) == "pong pong" )
| | | | |
| | ping pong false
| ping pong
Person ( Fred , 42 )
at com. eed3si9n. expecty. Expecty$ExpectyListener . expressionRecorded( Expecty . scala: 35 )
at com. eed3si9n. expecty. RecorderRuntime . recordExpression( RecorderRuntime . scala: 39 )
... 36 elided
例えば assert(...) で名前渡しの引数を使ったとしたら、その値を得るタイミングは制御できるが false しか得ることができない。一方マクロでは、person.say(word1, word2) == "pong pong" というソースコードの形そのものを受け取り、全ての式の評価値を含んだエラーメッセージを自動生成するということができる。頑張って書こうと思えば Predef.assert(...) を使っても手でこのようなエラーメッセージを書くことができるが、非常に退屈な作業となる。マクロの全貌はこれだけでは無い。
よくありがちな考え方としてコンパイラはソースコードをマシンコードへと翻訳するものだとものがある。確かにそういう側面もあるが、コンパイラは他にも多くの事を行っている。型検査 (type checking) はそのうちの一つだ。バイトコード (や JS) を最後に生成する他に、Scala コンパイラはライトウェイトな証明システムとして振る舞い、タイポや引数の型合わせなど様々なエラーを事前にキャッチする。Java の仮想機械は、Scala の型システムが何を行っているかをほとんど知らない。この情報のロスは、何か悪いことかのように型消去とも呼ばれるが、この型とランタイムという二元性によって Scala が JVM、JS、Native 上にゲスト・プログラミング言語として存在することができる。
2021-08-21
/ sbt
実験的 sbt として、酢鶏 (sudori) という小さなプロジェクトを作っている。当面の予定はマクロ周りを Scala 3 に移植することだ。sbt のマクロを分解して、土台から作り直すという課題だ。これは Scala 2 と 3 でも上級者向けのトピックで、僕自身も試行錯誤しながらやっているので、覚え書きのようなものだと思ってほしい。
参考:
Convert
何にも依存していない基礎となる Convert というものを特定できた。
abstract class Convert {
def apply[ T: c.WeakTypeTag ]( c: blackbox.Context )( nme: String , in: c.Tree ) : Converted [ c. type ]
....
}
Tree を受け取って Converted という抽象データ型を返す部分関数の豪華版みたいなものに見える。Converted は、以下のように型パラメータとして [C <: blackbox.Context with Singleton] を取る:
final case class Success [ C <: blackbox.Context with Singleton ](
tree: C # Tree ,
finalTransform: C # Tree => C# Tree
) extends Converted [ C ] {
def isSuccess = true
def transform( f: C # Tree => C# Tree ) : Converted [ C ] = Success ( f( tree), finalTransform)
}
このように直接 Tree、つまり抽象構文木 (AST) を扱う古い Scala 2 マクロの実装の典型的な例だが、Scala 3 ではもっと綺麗に高度なレベルでメタプログラミング を行う仕掛けとして inline などがあるので、そこから始めるのを通常は推奨される。
ただし、この場合は既存のマクロを移植しているのでクォートリフレクション (quote reflection) にひとっ飛びする。これは Scala 2 マクロに似ている感じだ。
2021-08-01
/ sbt
実験的 sbt として、酢鶏 (sudori) という小さなプロジェクトを作っている。当面の予定はマクロ周りを Scala 3 に移植することだ。sbt のマクロを分解して、土台から作り直すという課題だ。これは Scala 2 と 3 でも上級者向けのトピックで、僕自身も試行錯誤しながらやっているので、覚え書きのようなものだと思ってほしい。これはそのパート2だ。
参考:
Instance
build.sbt マクロと言われて思いつくのは .value を使った Applicative do マクロなんじゃないかと思う。呼び方としては、そうは呼ばない人もいるかもしれないが。この命令型から関数型への変換を担っているのは、ちょっと変わった名前を持つ Instance class のコンパニオンだ:
/**
* The separate hierarchy from Applicative/Monad is for two reasons.
*
* 1. The type constructor is represented as an abstract type because a TypeTag cannot represent a type constructor directly.
* 2. The applicative interface is uncurried.
*/
trait Instance {
type M [ x ]
def app[ K [ L [ x ]] , Z ]( in: K [ M ], f: K [ Id ] => Z)( implicit a: AList [ K ]) : M [ Z ]
def map[ S , T ]( in: M [ S ], f: S => T) : M [ T ]
def pure[ T ]( t: () => T) : M [ T ]
}
trait MonadInstance extends Instance {
def flatten[ T ]( in: M [ M [ T ]]) : M [ T ]
}
Scaladoc でも言及されているが、sbt は内部に独自の Applicative[_] 型クラスを定義している。Mark が 2012年 (Scala 2.10.0-M6 あたり) に列挙した 2つの理由が現時点でも当てはまるかは不明だ。マクロはこんな感じだ:
2021-04-26
sbt 1.5.1 パッチリリースをアナウンスする。リリースノートの完全版はここにある - https://github.com/sbt/sbt/releases/tag/v1.5.1 。本稿では Bintray から JFrog Artifactory へのマイグレーションの報告もする。
Bintray から JFrog Artifactory へのマイグレーション
まずは JFrog社に、sbt プロジェクトおよび Scala エコシステムへの継続的なサポートをしてもらっていることにお礼を言いたい。
sbt がコントリビューター数とプラグイン数において伸び盛りだった時期に Bintray の形をした問題があった。個人のコントリビューターに Ivy レイアウトのレポジトリを作って、sbt プラグインを公開して、しかし解決側では集約したいという問題だ。GitHub の sbt オーガニゼーションでプラグインのソースを複数人で流動的に管理することができるようになったが、バイナリファイルの配信は課題として残っていた。当時は sbt のバージョンもよく変わっていたというのがある。2014年に Bintray を採用して、成長期の配信メカニズムを担ってくれた。さらに僕たちは sbt の Debian と RPM インストーラーをホスティングするのに Bintray を使っていて、これは Lightbend 社が払ってくれている。
2021年2月、JFrog は Bintray サービスの終了をアナウンスした。その直後から、JFrog 社は向こうからコンタクトしてきて、何回もミーティングをスケジュールしてくれたり、open source sponsorship をグラントしてくれたり、マイグレーション用のツールキットをくれたりとお世話になっている。
今現在 Scala Center にライセンスされ、JFrog がスポンサーしてくれたクラウド・ホストな Artifactory のインスタンスが稼働している。「Artifactory のインスタンス」と何度も書くのが長いので、本稿では Artsy と呼ぶ。sbt 1.5.1 がリリースされたことで、マイグレーションは完了したと思う。
read 系
4月18日の時点で全ての sbt プラグインと sbt 0.13 アーティファクトを Artsy に移行して、Lightbend IT チームが https://repo.scala-sbt.org/scalasbt/ を Artsy を指すようにしてくれたため、既存のビルドは何もしなくてもそのまま動く はずだ。これは5月1日以降でも大丈夫なはずだ。もしもそうじゃないなら、issue が上がっているかチェックした後、報告をお願いします。
write 系
Artsy の sbt-plugin-releases はリードオンリーにする予定だ。そのため、プラグイン作者の人は、Sonatype OSSRH に移行する必要がある。organization 名の許可が下りたら、公開は sbt-ci-release で自動化できる。
2021-04-19
/ scala
猫番: 19日目 。FunctionK という Rúnar さんによるランク2多相性のエンコーディング、そして高ランク多相が可能にすると予見された Resource データ型に関して。
2021-02-16
/ sbt
sbt 1.1.0 で僕は統一スラッシュ構文を実装した。それから数年経った今日になって、古い sbt 0.13 でのシェル構文を廃止勧告するための pull request を送った。#6309
成り行きとして、build.sbt のための旧構文も廃止勧告にするという話題 が出てきた 。
「統一」スラッシュ構文がそう名付けられたのはシェル構文とビルド定義構文を統一するからだ。そのため、シェルの旧構文を廃止勧告するならば、skip in publish や scalacOptions in (Compile, console) というふうに in を使う旧 build.sbt 構文も同時に廃止勧告するというのは理にかなっている。
build.sbt を統一スラッシュ構文へと変換する syntactic Scalafix rule をちゃちゃっと作ったのでここで紹介する - https://gist.github.com/eed3si9n/57e83f5330592d968ce49f0d5030d4d5
用法
プロジェクトを git で管理するか、バックアップを取ること。
$ cs install scalafix
$ export PATH= " $PATH: $HOME/Library/Application Support/Coursier/bin"
$ scalafix --rules= https://gist.githubusercontent.com/eed3si9n/57e83f5330592d968ce49f0d5030d4d5/raw/7f576f16a90e432baa49911c9a66204c354947bb/Sbt0_13BuildSyntax.scala *.sbt project/*.scala
完全には正確じゃないが、手動で全部やるよりはマシだと思う。
2021-02-06
/ git
git bisect はバグの入った場所を特定するのに有用なテクニックだ。 特に scala/scala の場合は、bisect.sh はビルド済みのコンパイラを Scala CI Artifactory から利用することで時間を節約できる。
2020-12-14
/ scala
Rob wrote :
I want to tell sbt “this specific version breaks binary compatibility, so don’t resolve it via eviction, fail the build instead.” How do I do this? Complete answers only, I’m done trying to figure it out by following clues.
sbt に「この特定のバージョンはバイナリ互換性を壊すからバージョンの解決をしないでビルドを失敗して」と言いたい。これはどうやるんだろうか? ヒントを追うのに疲れたので、完全な回答のみ募集。
これを行う小さな sbt プラグイン sbt-strict-update を書いた。
project/plugins.sbt に以下を追加:
addSbtPlugin( "com.eed3si9n" % "sbt-strict-update" % "0.1.0" )
そして build.sbt にこれを書く:
ThisBuild / libraryDependencySchemes += "org.typelevel" %% "cats-effect" % "early-semver"
それだけだ。
ThisBuild / scalaVersion : = "2.13.3"
ThisBuild / libraryDependencySchemes += "org.typelevel" %% "cats-effect" % "early-semver"
lazy val root = ( project in file( "." ))
. settings(
name : = "demo" ,
libraryDependencies ++= List (
"org.http4s" %% "http4s-blaze-server" % "0.21.11" ,
"org.typelevel" %% "cats-effect" % "3.0-8096649" ,
),
)
もし Rob さんが上のビルドを compile しようとすると以下のように失敗するはずだ:
2020-12-01
/ sbt
本稿は前に書いたTravis-CI からの sbt プラグインの自動公開 の GitHub Actions 版だ。
Ólaf さんの olafurpg/sbt-ci-release を使って sbt プラグインのリリースを自動化してみる。sbt-ci-release の README は Sonatype OSS 向けの普通のライブラリのリリースを前提に書かれている。sbt プラグインのリリースに必要な差分以外の詳細は README を参照してほしい。
リリースを自動化することそのものがベスト・プラクティスだが、sbt プラグインのリリースに関連して特に嬉しいことがある。この方法を使うことで Bintray の sbt organization にユーザーを追加せずに、複数人で sbt プラグインのリリース権限を共有することが可能となる。これは仕事でメンテしているプラグインがあるときに便利だ。
step 1: sbt-ci-release
sbt-release を使っている場合は削除する。sbt-ci-release を追加する。
addSbtPlugin( "org.foundweekends" %% "sbt-bintray" % "0.6.1" )
addSbtPlugin( "com.geirsson" % "sbt-ci-release" % "1.5.4" )
addSbtPlugin( "com.jsuereth" % "sbt-pgp" % "2.1.1" ) // for gpg 2
version.sbt も削除する。
step 2: -SNAPSHOT version
sbt-dynver を多少抑えて、タグの付いていないコミットで -SNAPSHOT バージョンを使えるようにする:
ThisBuild / dynverSonatypeSnapshots : = true
ThisBuild / version : = {
val orig = ( ThisBuild / version). value
if ( orig. endsWith( "-SNAPSHOT" )) "2.2.0-SNAPSHOT"
else orig
}
step 3: sbt-bintray セッティングを復活させる
プラグインは通常 sbt-bintray を使ってリリースするので、publishTo を bintray / publishTo に戻す。publishMavenStyle を false にする。
2020-11-29
/ scala
本稿は 2018年12月に 4.0.0-RC2 と共に初出した。2020年11月にリリースした 4.0.0 での変更を反映して更新してある。
最近 scopt 4.0 を書いている。せっかちな人は readme に飛んでほしい。
4.0.0 を試すには以下を build.sbt に書く:
libraryDependencies += "com.github.scopt" %% "scopt" % "4.0.0"
scopt 4.0.0 は以下のビルドマトリックスに対してクロスパブリッシュされている:
Scala
JVM
JS (1.x)
JS (0.6.x)
Native (0.4.0-M2)
Native (0.3.x)
3.0.0-M2
✅
✅
n/a
n/a
n/a
3.0.0-M1
✅
✅
n/a
n/a
n/a
2.13.x
✅
✅
✅
n/a
n/a
2.12.x
✅
✅
✅
n/a
n/a
2.11.x
✅
✅
✅
✅
✅
scopt はコマンドラインオプションをパースするための小さなライブラリだ。2008年に aaronharnly/scala-options として始まり、当初は Ruby の OptionParser を緩めにベースにしたものだった。scopt 2 で immutable parsing を導入して、scopt 3 では Read 型クラスを使ってメソッド数を大幅に減らすことができた。
2020-10-25
/ sbt
sbt と Zinc 1.4.x 系列で僕が時間と力をかけたのはおそらくファイルの仮想化とタイムスタンプを抜き出すことだ。この組み合わせによりマシン特定性と時から Zinc の状態を解放することができ、Scala のための差分リモートキャッシュを構築するための礎となる。これに関してsbt でのコンパイルキャッシュ を書いた。これはその続編となる。
sbt 1.4.x が出たので、この機能を実際に使ってみたいという気運が一部高まっている。
リモートキャッシュサーバー
リモートキャッシュを運用するには、リモートキャッシュサーバーが必要となる。初期のロールアウトでは、追加でサーバーを用意せずに簡単に試せるように Maven リポジトリ (MavenCache("local-cache", file("/tmp/remote-cache")) を含む) と互換を持たせるようにした。次のステップはこのリモートキャッシュをマシン間で共有することだ。
とりあえず JFrog Bintray は Maven リポジトリとして振る舞うことができるという意味で良いフィットなんじゃないかと思う。Bintray に publish を行うには RESTful API を経由する必要があって、それは sbt-bintray がカプセル化している。
ちなみに Bazel は HTTP プロトコルか gRPC を用いたリモートキャッシュのサポートを提供し、これは Nginx、bazel-remote、Google Cloud Storage、その他 HTTP を話せるモノなら何でも実装できる。ライブラリ依存性と違って特に resolve する必要が無いので将来的にはそのような方向に移行するのが良いと思う。
sbt-bintray-remote-cache
今すぐリモートキャッシュを使ってみたいという人のために、sbt-bintray のスピンオフとして sbt-bintray-remote-cache というプラグインを作った。
使うには以下を project/plugins.sbt に追加する:
addSbtPlugin( "org.foundweekends" % "sbt-bintray-remote-cache" % "0.6.1" )
Bintray リポとパッケージ
次に、https://bintray.com/<your_bintray_user>/ に行って、新しい Generic なリポジトリを remote-cache
それから、remote-cache リポジトリ内にパッケージを作る。基本的には 1つのビルドに対して 1つのパッケージを作る。
認証情報
リモートキャッシュに push するには、Bintray の認証情報 (ユーザ名と API key) を認証ファイルもしくは環境変数にて渡す必要がある。ローカルでは sbt-bintray と同じ認証ファイルを使うことができる ($HOME/.bintray/.credentials)。CI マシーンでは sbt-bintray と異なる 環境変数を使う:
2020-10-19
sbt 1.4.1 パッチリリースをアナウンスする。リリースノートの完全版はここにある - https://github.com/sbt/sbt/releases/tag/v1.4.1
アップグレード方法
公式 sbt ランチャー を SDKMAN か https://www.scala-sbt.org/download.html からダウンロードしてくる。このインストーラーには sbtn のバイナリが含まれている。
次に、使いたいビルドの project/build.properties ファイルに以下のように書く:
この機構によって使いたいビルドにだけ sbt 1.4.1 が使えるようになっている。
主な変更点
その他は https://github.com/sbt/sbt/releases/tag/v1.4.1 を参照
参加
sbt 1.4.1 は 9名のコントリビューターにより作られた。 Ethan Atkins, Eugene Yokota (eed3si9n), Adrien Piquerez, Kenji Yoshida (xuwei-k), Nader Ghanbari, Taichi Yamakawa, Andrii Abramov, Guillaume Martres, Regis Desgroppes。この場をお借りしてコントリビューターの皆さんにお礼を言いたい。また、これらのコントリのいくつかは ScalaMatsuri 2020 中のハッカソン にて行われた。
2020-10-19
/ scala
本稿は ScalaMatsuri Day 2 アンカンファレンスで OSS ハッカソンを仮想化したことのレポートだ。誰かがアンカンファレンスのトピックとして提案したらしく、僕は朝会でファシリテーターとして申し出ただけなので事前準備は特に無し。元々は 4時間 (JST 正午 - 4pm、EDT 11pm - 3am) で枠をもらったが、うまく回ったのでコーヒーブレイクの後も数時間続いた。
アンカンファレンスをやるときにいつも強調してるのは「二本足の法則」で:
いつでも自分にとってその場からの「学び」や自分から場への「貢献」が無いなと感じた場合: 自分の二本足を使って別の場へ移動すること
オンラインのアンカンファレンスで、複数のセッションが行われているので別のトークを見るために抜けたり途中から参加することは自由であることを事前に伝えた。
使ったもの
Zoom Meeting
Discord
Google Docs
主なコミュニケーションは ScalaMatsuri が用意していた Zoom Meeting を使った。これで異なる参加者が自分の画面を共有したり質問をしたりできる。潜在的な問題としては、全員が他の人全員を聞こえる状態になるので、複数のグループが同時にペアプログラムをしたいといった状況には向かない。
テキストベースのコミュニケーションとしては Discord を使った。Discord はリンクを共有したり、質問をしたりにも使う。僕たちはやらなかったが、Discord のボイスチャンネルを使って画面の共有 も可能なのでプロジェクト毎にボイスチャンネル分かれるという使う方もできると思う。
プロジェクトと GitHub issue の列挙、どの作業をしたりのかのサインアップには Google Doc 一枚を使った。
流れ
メンターをできるプロジェクトメンテナの人が参加してるかを聞く
プロジェクトメンテナは他の人が手を付けやすい good first な GitHub issue を Google doc に書いて、Zoom でその簡単な説明をする。
参加者は issue の隣に自分の名前を書いてサインアップする (ペアで一つの issue に取り組むことも可)
プロジェクトメンテナは単体テストと統合テスト (scala/scala だと partest、sbt/sbt だと scripted) の走らせ方を解説
自分も共同作業する場合はプロジェクトメンテナはもっとチャレンジングなタスクを提案してもいい
人の出入りがあるので、上記をリピート
基本的にはミュートしてハック
ファシリテーターは、皆が作業するものがあるかどうかの確認を定期的に行う
誰かがタスクを完了したら成功でも失敗でも Zoom で軽く発表する。(参加者が多い場合はこれは1日の最後にやってもいい)
scala/scala
Scala のコンパイラや標準ライブラリが開発される scala/scala にコントリビュートに興味がある人が多かった。明らかなバグ修正じゃない場合は scala/scala へのプルリクは数ヶ月放置されたりする可能性もある旨を注意した。