Tree-sitter を用いた Scala 3 の高速パース
これは Scala Advent Calendar 2022 23日目の記事です。昨日は、Windymelt さんの4つのプラグインを活用して、Scalaソフトウェアを楽々リリースしようでした。
2021年の中頃に Chris Kipp さんがやっている Tooling Talks というポッドキャストに出させてもらった。そこで話すネタとして考えておいたのは「ツーリングとは何か」という質問だ。僕は、自分のことは普通のプログラマだという認識だが、他社の人と会っても「tooling people だな」と判別できたりする。という事はやっぱり、ツーリングという「何か」があるんだと思う。たとえ話で説明したのは、例えば家を建てたり楽器を作るとき、多くの人は実際に家や楽器となる木材を切ったりという作業を行うが、脇の方で 10本の木材を同時に切ることで効率化したり、その家特定の角度できる事を簡単にしたりということをやってる人たちが数人いたりする。その人達が tooling people だ。
他の tooling people と話す機会が多いからか、以前から Tree-sitter とか、Tree-sitter 文法がどうしたこうしたということを耳にすることがあったが、先週までちゃんと調べていなかった。
Tree-sitter とは何か?
Tree-sitter は、2017年に Max Brunsfeld さんにより発表されたパーサ生成ツールと差分パース・ライブラリで、その時点で 4年越しで開発を行い、当初は趣味プロジェクトで後ほど Github社として開発を行っていたらしい。 彼の Strange Loop でのトークは Tree-sitter の素晴らしい導入だと思う。 そのトークによると、Tree-sitter は Atom でのパースや、github.com の一部の実験的機能に用いられたらしい。
使い始めるには、tree-sitter という Tree-sitter のコマンド・ラインツールをインストールする。
これは、grammar.js を処理して C言語で書かれたパーサを生成する。
この一連の作業は、大学で習った yacc/bison でのパーサ生成を彷彿とさせる。
一般的なパーシング・ライブラリにありがちな実行時に正規表現を実行するのに比べると、これらの生成器は有限状態機械へと分解しているため、より高速なパースが期待できる。
Tree-sitter の機能で興味深いのは、差分パースできるとこと、エラーを含んだコードでもパースできることだ。これらの 2つの側面から、Tree-sitter は特にエディタにおける構文ハイライトやコード畳み込みなどの言語特化機能と相性が良いといえるだろう。
言語サーバプロトコル (LSP) 同様に、Tree-sitter 本体は特定のプログラミング言語には関与しないが、好みの言語に対する C言語パーサを生成してやると、それを用いてプログラム上からソースコードを解析することができる。便宜的に考えると、tree-sitter CLI は、ありとあらゆるソースコードを LISP へと変換することができると思えばいい。
一旦、コードを共通のフォーマットに落とし込むことができれば、他の人はそのコードを操作するツール(構文ハイライト以外にも色々ある)を汎用的に書くことができる。
Neovim と Tree-sitter と Scala
Vim はキーワード検索を使った構文ハイライト機能が提供されていて、使えないことは無いが、Sublime Text や VS Code といったその他のエディタと比べると、構文ハイライトの精度は劣っている。 Neovim は次世代の構文ハイライトに Tree-sitter を採用する予定で、現行版でも nvim-treesitter を用いて実験的に使うことができ、ハイライトの精度が理論上は向上するということになっている。
僕が先週の火曜日に使ってみた感じだと、Scala 3 の中括弧省略構文のハイライトは酷かった。 前述の通り、Tree-sitter 本体は特定のプログラミング言語に関与しないが、tree-sitter/tree-sitter-scala という別のリポジトリにて Scala 用の Tree-sitter 文法がメンテされていて、どうやらそれが Scala 3 で導入された新構文に対応していない様子だ。
Tree-sitter が Scala 3 のコードを処理できるようになると、より豊かな言語解釈 (スコープとも呼ばれる) を行うことができるため、パースされた構文木を使ってより良い構文ハイライトや、その他の機能が使えるようになることが期待できる。「自転車置場 (bikeshed) の屋根のペンキの色」は凡俗法則の極北かもしれないが、冬休み中の Scala 3 勢としては、この yacc は自分のことを呼んでいるような気がした。
EBNF からの変換
Scala 3 の構文は Scala 3 Reference: Scala 3 Syntax Summary において EBNF (拡張 Backus–Naur 形式) で公開されている。 Ethan Atkins さんが、放置した tree-sitter-ebnf-generator というレポジトリがあって、それで2者を変換できる可能性がある。少しいじってみたが、Tree-sitter の理解がまだ足りなくてうまくいかなかった。
しかし、一般的に、このようなパーサの書き換えを行う場合、EBNF での構文定義を参照することは有用かつ重要だ。
Note: catch
初期の Scala 言語仕様では catch は case ブロックを受け取るように書かれていた。2015年に、Som Snytt (@som_snytt@fosstodon.org) さんがこれを式へと一般化する ‘Can catch any expression’ (scala/scala#4400) を送った。数年越しのレビューは難航したが、ついに 2021年にこれがマージされ Scala 2.13.6 としてリリースされた。
これをもって catch 節は、通常の全体関数を引数として受け取ることが可能となり、部分関数リテラル「{ case e => ... }」を渡すのは「慣例」、catch はメソッドでもいいのではないか、と言うこともできる。
tree-sitter-scala をハックする
tree-sitter-scala を改造する作業は慣れるとそこまで難しくない。
npm install
次に、./corpus 以下にあるテストファイルを変更して、以下を実行する:
npm run build
npm test
tree-sitter CLI 自体は Rust で書かれているらしい。上記の npm run build は CLI を呼び出すが、tree-sitter-scala のコード生成に時間がかかる。僕の古いラップトップでこの処理に 5分ぐらいかかり、文法の変更によってはそれが 10~40分に跳ね上がり、最終的に終わるのかどうか分からなくなったりする。そのため、丸一日作業しても1時間のうちに 10個の変更を試すのがやっとだ。
とりあえず現状の確認ということで、以下は Scala 3 構文のコードを抜粋したものを Sonokai 配色でハイライトさせたものだ。この配色は Tree-sitter 互換なので、異なる要素を色付けして区別しようとしているのが分かるはずだ:
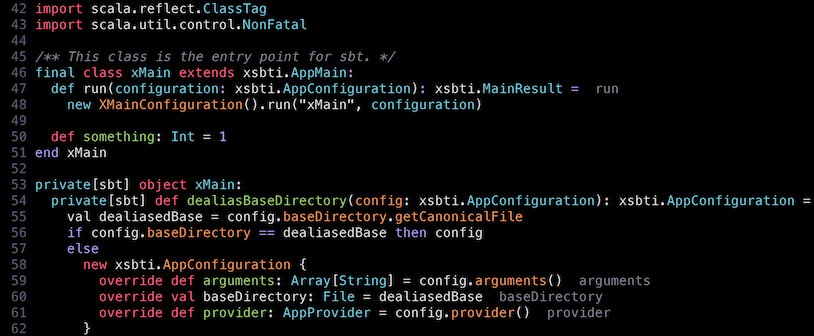
中括弧省略構文を認識しないため、def run がハイライトされていないことに注目してほしい。
中括弧省略構文、パート1
先週の火曜日に ‘Optional braces, part 1’ (#61) というプルリクを tree-sitter-scala に初めて出して、主な変更点は以下のようになっていた:
- template_body: $ => seq(
- '{',
- // TODO: self type
- optional($._block),
- '}'
+ /*
+ * TemplateBody ::= :<<< [SelfType] TemplateStat {semi TemplateStat} >>>
+ */
+ template_body: $ => choice(
+ prec.left(PREC.end_decl, seq(
+ ':',
+ // TODO: self type
+ // TODO: indentation. currently second `val` declaration in the block will
+ // be treated as a top-level declaration instead of belonging to the template.
+ $._block,
+ optional($._end_signifier),
+ )),
+ seq(
+ '{',
+ // TODO: self type
+ optional($._block),
+ '}',
+ ),
),
template_body というのはクラスやオブジェクトの定義の本体部で、この変更は { ... } の代わりに : を使えるようにするというものだ。小さい変更で、色々正しくパースしないコードもあると思うが、def run がメソッドだと認識されることが分かる:
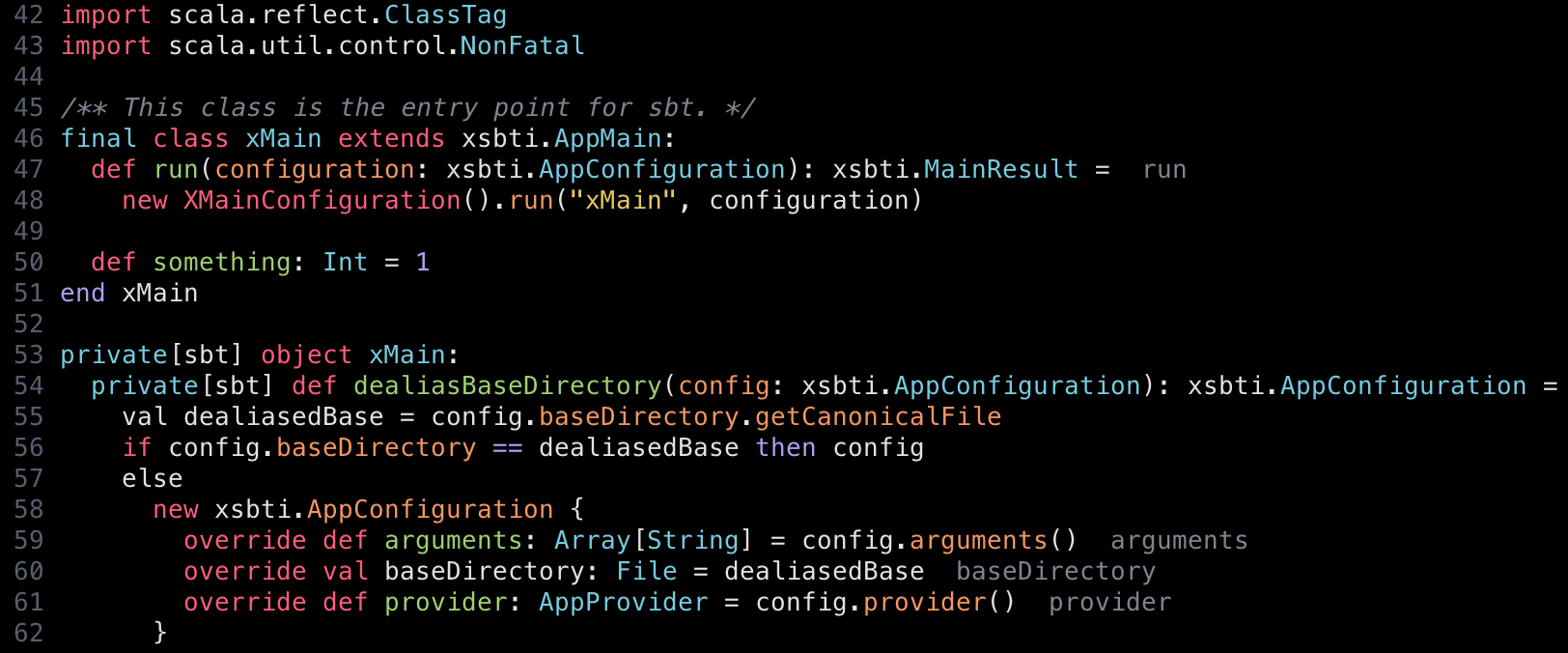
中括弧省略構文、パート2
上の例では val dealiasedBase が正しくハイライトされていないのが目立つ。
これは Scala 2 では val 定義は必ず { ... } ブロックを必要としていたからだ。
これに関しても上辺だけを取り繕って { ... } の要件だけを抜くことができるが、中括弧省略構文においてある構文がどの親に属するかを判別するには大まかな方向として、インデント・レベルを追跡する必要がある。
class A:
def foo(): Unit =
val x = 1
val y = 2
上記では、val y は def foo に属する。
class A:
def foo(): Unit =
val x = 1
val y = 2
上記では、val y は def foo ではなく class A に属する。
class A:
def foo(): Unit =
val x = 1
val y = 2
上記では、val y はトップレベル文となる。これは一部で注目を集めているエリアなので、2週間ぐらい前に Anton Sviridov さんが既に調べ始めていた事を知っても驚かなかった。wip ブランチを教えてもらった。
Tree-sitter 文法で、末端トークンは
'def' のような素の文字列か正規表現によって表されられるが、正規表現だと不可能もしくは不便な場合がある。そこで、外部スキャナーという機能を使って、C言語で実装したプログラムのスキャナーを提供することができる。例えば、tree-sitter-scala は文字列リテラルのために既に外部スキャナーを使っていて、これは """...""" 内で改行の扱いが変わることを考慮すると理にかなっているといえる。Anton さんが彼の work-in-progress ブランチで始めていたのはインデント・レベルを C言語で書かれたスタックで追跡するインデント/アウトデントのための外部スキャナーの実装だ。 素の C言語を書くのは多分それこそ大学のコンパイラ講座で Bison とかを使って以来だと思うので、この Tree-sitter というのは僕的にはレトロフューチャーなノリを感じる。
$._indent と $._outdent を使って template_body を変更して、if 式の中などで使える新しい _indentable_expression というトークンを定義した:
template_body: $ => choice(
prec.left(PREC.end_decl, seq(
':',
// TODO: self type
- // TODO: indentation. currently second `val` declaration in the block will
- // be treated as a top-level declaration instead of belonging to the template.
+ $._indent,
$._block,
+ $._outdent,
optional($._end_signifier),
)),
....
+ _indentable_expression: $ => choice(
+ $.indented_block,
+ $.expression,
+ ),
block: $ => seq(
'{',
optional($._block),
'}'
),
+ indented_block: $ => seq(
+ $._indent,
+ $._block,
+ $._outdent,
+ ),
文法を試す方法として、tree-sitter CLI は test コマンドを提供して、テストはコードの抜粋と期待される S式を書いたテキストファイルで表現される:
=======================================
Function definitions (Scala 3 syntax)
=======================================
class A:
def foo(c: C): Int =
val x = 1
val y = 2
x + y
---
(compilation_unit
(class_definition
(identifier)
(template_body
(function_definition
(identifier)
(parameters
(parameter (identifier) (type_identifier)))
(type_identifier)
(indented_block
(val_definition (identifier) (integer_literal))
(val_definition (identifier) (integer_literal))
(infix_expression (identifier) (operator_identifier) (identifier)))))))
上の例では、2つの val_declaration ノードがあり、両方とも indented_block に属することが分かる。
これが、さっき僕が tree-sitter は全てのコードを LISP に変換すると言っていた理由だ。
インデント/アウトデント追跡無しだと val y が def foo に属するかの判定は確実にはつかないだろう。
中括弧省略構文、パート2.a
すぐに気付いたのは、以下のようなコードをパースしようとすると失敗することだ:
class A:
def foo(): Unit =
val x = 1
class B
tree-sitter CLI の parse コマンドを使うと以下のように表示される:
$ tree-sitter parse examples/A.scala
(compilation_unit [0, 0] - [5, 0]
(class_definition [0, 0] - [5, 0]
name: (identifier [0, 6] - [0, 7])
body: (template_body [0, 7] - [5, 0]
(function_definition [1, 2] - [4, 0]
name: (identifier [1, 6] - [1, 9])
parameters: (parameters [1, 9] - [1, 11])
return_type: (type_identifier [1, 13] - [1, 17])
body: (indented_block [2, 4] - [4, 0]
(val_definition [2, 4] - [2, 13]
pattern: (identifier [2, 8] - [2, 9])
value: (integer_literal [2, 12] - [2, 13]))))
(ERROR [4, 0] - [4, 7]
(identifier [4, 0] - [4, 5])
(identifier [4, 6] - [4, 7])))))
examples/A.scala 0 ms (ERROR [4, 0] - [4, 7])
備考: ロバストなパース
(パーサ自体の限界のため) コードの一部をパースすることを失敗しても、完全に失敗はせずに、構文木の大部分を結果として返すことができたことに注目してほしい。
先ほど出した例でもパースに失敗する:
class A:
def foo(): Unit =
val x = 1
val y = 2
何が起こっているのか解説するために INDENT と OUTDENT トークンをコードに書き出してみる:
class A:
INDENT
def foo(): Unit =
INDENT
val x = 1
OUTDENT
val y = 2
パーサは 2つの OUTDENT を期待するが、代わりに class もしくは val が出てきてしまって、失敗することになる。
これは基本的には、インデント/アウトデント追跡のバグだと言える:
bool tree_sitter_scala_external_scanner_scan(void *payload, TSLexer *lexer,
const bool *valid_symbols) {
// read all the whitespaces and newlines
if (valid_symbols[OUTDENT] && newline_count > 0 && prev != -1 &&
indentation_size < prev) {
popStack(stack);
lexer->result_symbol = OUTDENT;
return true;
}
....
それぞれのトークンに対してスキャナーが呼ばれ、indentation_size が改行後に減少した場合のみ OUTDENT が返される。
これは単独だとうまくいくが、最初の OUTDENT 以降はこの条件にヒットしなくなる。
僕が行って修正はインデントレベルを保存して、関数の頭で他の文字を処理する前に OUTDENT を再度返せるか確かめるというものだ:
bool tree_sitter_scala_external_scanner_scan(void *payload, TSLexer *lexer,
const bool *valid_symbols) {
ScannerStack *stack = (ScannerStack *)payload;
int prev = peekStack(stack);
// Before advancing the lexer, check if we can double outdent
if (valid_symbols[OUTDENT] &&
(lexer->lookahead == 0 || (
stack->last_indentation_size != -1 &&
prev != -1 &&
stack->last_indentation_size < prev))) {
popStack(stack);
lexer->result_symbol = OUTDENT;
return true;
}
stack->last_indentation_size = -1;
....
Scala のパーサを再構築して、もう一度試してみる:
$ time npm run build && say ok
> tree-sitter-scala@0.19.0 build
> tree-sitter generate && node-gyp build
gyp info it worked if it ends with ok
gyp info using node-gyp@9.0.0
gyp info using node@18.4.0 | darwin | x64
gyp info spawn make
gyp info spawn args [ 'BUILDTYPE=Release', '-C', 'build' ]
CC(target) Release/obj.target/tree_sitter_scala_binding/src/parser.o
CXX(target) Release/obj.target/tree_sitter_scala_binding/bindings/node/binding.o
CC(target) Release/obj.target/tree_sitter_scala_binding/src/scanner.o
SOLINK_MODULE(target) Release/tree_sitter_scala_binding.node
gyp info ok
npm run build 129.23s user 260.38s system 55% cpu 11:41.38 total
$ tree-sitter parse examples/A.scala
(compilation_unit [0, 0] - [5, 0]
(class_definition [0, 0] - [4, 0]
name: (identifier [0, 6] - [0, 7])
body: (template_body [0, 7] - [4, 0]
(function_definition [1, 2] - [4, 0]
name: (identifier [1, 6] - [1, 9])
parameters: (parameters [1, 9] - [1, 11])
return_type: (type_identifier [1, 13] - [1, 17])
body: (indented_block [2, 4] - [4, 0]
(val_definition [2, 4] - [2, 13]
pattern: (identifier [2, 8] - [2, 9])
value: (integer_literal [2, 12] - [2, 13]))))))
(val_definition [4, 0] - [4, 9]
pattern: (identifier [4, 4] - [4, 5])
value: (integer_literal [4, 8] - [4, 9])))
val y が正しく compilation_unit の子ノードとパースされたことが分かる。
中括弧省略構文、パート2.b
興味深いことに、以下の例も別の理由によって失敗する:
class A:
def foo: Int =
1
val y = 2
エラーを見ると、val y = 2 は class A の一部となることに失敗したようだ。
これは、アウトデントが改行文字を取ってしまったため、テンプレート内のメソッドやフィールドの間に入れる自動セミコロン検知がうまくいかなくなったせいだと考えられる:
_block: $ => prec.left(seq(
sep1($._semicolon, choice(
$.expression,
$._definition,
$._end_marker,
)),
optional($._semicolon),
)),
_semicolon: $ => choice(
';',
$._automatic_semicolon
),
スキャナーにインデントレベルを保存させたのと同様に、改行数を保存して自動セミコロン検知が改行数を使えるようにする。
bool tree_sitter_scala_external_scanner_scan(void *payload, TSLexer *lexer,
const bool *valid_symbols) {
// read all the whitespaces and newlines
if (valid_symbols[OUTDENT] &&
(lexer->lookahead == 0 || (
newline_count > 0 &&
prev != -1 &&
indentation_size < prev))) {
popStack(stack);
LOG(" pop\n");
LOG(" OUTDENT\n");
lexer->result_symbol = OUTDENT;
stack->last_indentation_size = indentation_size;
stack->last_newline_count = newline_count;
stack->last_column = lexer->get_column(lexer);
return true;
}
// Recover newline_count from the outdent reset
if (stack->last_newline_count > 0 &&
lexer->get_column(lexer) == stack->last_column) {
newline_count += stack->last_newline_count;
}
....
もう1度試してみる:
$ time npm test
# test passed
$ tree-sitter parse examples/A.scala
(compilation_unit [0, 0] - [5, 0]
(class_definition [0, 0] - [5, 0]
name: (identifier [0, 6] - [0, 7])
body: (template_body [0, 7] - [5, 0]
(function_definition [1, 2] - [4, 2]
name: (identifier [1, 6] - [1, 9])
return_type: (type_identifier [1, 11] - [1, 14])
body: (indented_block [2, 4] - [4, 2]
(integer_literal [2, 4] - [2, 5])))
(val_definition [4, 2] - [4, 11]
pattern: (identifier [4, 6] - [4, 7])
value: (integer_literal [4, 10] - [4, 11])))))
val y が正しくクラスの一部としてパースされたことが分かる。
中括弧省略構文、パート2.c
インデント/アウトデントの基本がうまくいった後、if、try、match、while、for 式などの制御構文を追加した。
Tree-sitter 文法を書くのにまだ慣れてないのと、毎回の手順に時間がかかるせいで、試行錯誤の連続だった。 以下に、色々自分がハマったポイントを書いていく。
Tree-sitter vs 文脈自由文法
これは tree-sitter-scala の実装に特定の癖なのか Tree-sitter 一般に関する問題なのか分からないが、Tree-sitter 文法は僕が知っている典型的な BNF とは少し異なる形で書かれている。
Scala 3 Syntax に出てくるような従来の (E) BNF は、曖昧さが無い深い階層を持ったトークンとして定義されることが多い:
Expr ::= FunParams ('=>' | '?=>') Expr
| HkTypeParamClause '=>' Expr
| Expr1
Expr1 ::= ['inline'] 'if' '(' Expr ')' {nl} Expr [[semi] 'else' Expr]
....
| PostfixExpr [Ascription]
PostfixExpr ::= InfixExpr [id]
InfixExpr ::= PrefixExpr
| InfixExpr id [nl] InfixExpr
PrefixExpr ::= [PrefixOperator] SimpleExpr
SimpleExpr ::= SimpleRef
| Literal
| '_'
| BlockExpr
....
| SimpleExpr ArgumentExprs
それに比べ、tree-sitter-scala はかなりフラットな感じだ。
expression: $ => choice(
$.if_expression,
$.match_expression,
$.try_expression,
$.call_expression,
$.assignment_expression,
$.lambda_expression,
$.postfix_expression,
$.ascription_expression,
$.infix_expression,
$.prefix_expression,
....
$.generic_function,
),
これは Tree-sitter が同じコード片を異なる方法でパースできるという衝突が頻繁に発生することになる。 ドキュメンテーションの Conflicting tokens 節がこの解説を行っている。 解決法の一つとして字句の優先順位が挙げられていて、これは演算子の優先順位に関連するが異なるものだ。
if 1 < 2 then 3
else 4 + 5
少し変だと思うかもしれないが、上記のコードは 2通りの方法でパースでき、3 か 8 となる。普通の方法そして以下の方法だ:
(if 1 < 2 then 3
else 4) + 5
直感的に中置記法の優先順位は低いだろうと思うかもしれないが、実は if 式はより低い優先順位を持つ。
Tree-sitter はトークンレベルで PREC 順位を割り当てることで解決する:
const PREC = {
control: 1,
...
infix: 6,
...
}
if_expression: $ => prec.right(PREC.control, seq(
'if',
...
)),
infix_expression: $ => prec.left(PREC.infix, seq(
field('left', $.expression),
...
)),
ここでは、大きい数字が高い優先順位を持つ。
より多くの階層を導入することで制御構文と低レベルな call_expression や infix_expression といった式が混ざらないのが理想的だ。
しかし、これまでの所式階層を増やすとビルド時間も劇的に上がって完了するか分からないこともあった。
識別子トークン
使い初めでよく分かってなくて、正直今もちゃんと理解できているか怪しい機能として自動キーワード抽出がある。
この機能は、yieldSomething のようにキーワードから始まる文字列が yield Something としてパースされてしまうのを防ぐらしい。僕がよく分かってないのはこれが yield を識別子として解釈されるのを防げるかどうかだ。
以下のコードを例に説明する:
def main() =
if
val a = false
a
then b
else c
if 条件節をインデント可能にする前は、Tree-sitter はのほほんと上のコードを以下のようにパースしてきた:
$ tree-sitter parse examples/A.scala
(compilation_unit [0, 0] - [6, 0]
(function_definition [0, 0] - [6, 0]
name: (identifier [0, 4] - [0, 8])
parameters: (parameters [0, 8] - [0, 10])
body: (indented_block [1, 2] - [6, 0]
(if_expression [1, 2] - [5, 8]
condition: (assignment_expression [2, 4] - [3, 5]
left: (postfix_expression [2, 4] - [2, 9]
(identifier [2, 4] - [2, 7])
(identifier [2, 8] - [2, 9]))
right: (postfix_expression [2, 12] - [3, 5]
(boolean_literal [2, 12] - [2, 17])
(identifier [3, 4] - [3, 5])))
consequence: (identifier [4, 7] - [4, 8])
alternative: (identifier [5, 7] - [5, 8])))))
これは postfix_expression 同士の assignment_expression だとパースされたことに注意してほしい。つまり、Tree-sitter は val を識別子だとパースしたわけだが、これは絶対に起こってはならないことだ。
微妙に関連する話題として、end_marker などで identifier を捕捉したくなくて、単に同じ正規表現を使いたい場面があるが、Tree-sitter は同じ正規表現を自動的にまとめて以下のような分かりづらいエラーを表示する:
Non-terminal symbol 'identifier' cannot be used as the word token
この正しい回避方法は以下のように文字列リテラルを使って識別子のエイリアスを定義することだ。
alias($.identifier, '_end_ident'),
中括弧省略構文、パート2 のプルリクエスト
先週の水曜日に ‘Optional braces, part 2’ (#62) を送って、それから一週間かけて今まで書いてきた内容のコミットを色々追加した。
Neovim の Tree-sitter サポートで便利なのは、生成された C言語のコードを取得するのに 適当なディレクトリや Github リポジトリを指定してその場で構文ハイライトが改善したか確認できることだ。
ビフォー:
アフター:
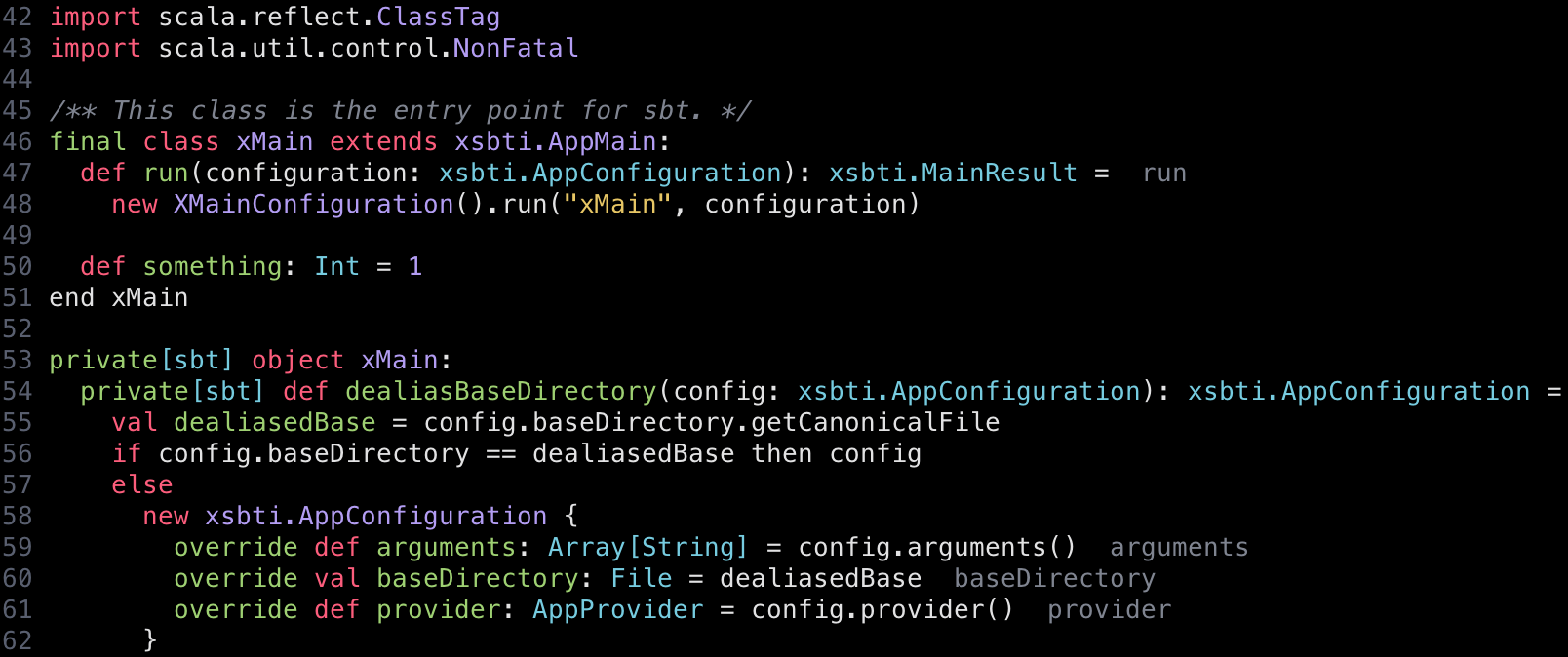
Scala 3 の新構文はまだまだ完全にサポートされたわけでは無いが、現状と比べるとまあまあ改善と言えると思う。
tree-sitter-scala フォークを使うための Neovim 設定
2月ぐらいに書かれたプルリクエストが放置されていたりするので、僕のプルリクがいつ考慮されるのかは不明な所がある。
幸いなことに nvim-treesitter は特定の言語の文法をオーバーライドする機能がある。 以下は今回紹介したものを自分のマシンで試す設定だ。
rm -f ~/.local/share/nvim/site/pack/packer/start/nvim-treesitter/parser/scala.so
lua/plugins.lua
vim.cmd [[packadd packer.nvim]]
return require('packer').startup(function()
-- Packer can manage itself
use 'wbthomason/packer.nvim'
use 'tanvirtin/monokai.nvim'
use 'sainnhe/sonokai'
use 'nvim-treesitter/nvim-treesitter'
end)
init.vim
lua << END
require('plugins')
require'nvim-treesitter.configs'.setup {
-- A list of parser names, or "all". Don't include "scala" here.
ensure_installed = { "c", "lua", "rust" },
sync_install = false,
auto_install = true,
highlight = {
enable = true,
additional_vim_regex_highlighting = false,
},
}
local parser_config = require "nvim-treesitter.parsers".get_parser_configs()
parser_config.scala = {
install_info = {
-- url can be Git repo or a local directory:
-- url = "~/work/tree-sitter-scala",
url = "https://github.com/eed3si9n/tree-sitter-scala.git",
branch = "fork-integration",
files = {"src/parser.c", "src/scanner.c"},
requires_generate_from_grammar = false,
},
}
END
高速な Scala 3 のパース
Scala 3 コンパイラのコードをいくつかパースしてみよう。Scala 3 コンパイラで大き目のソース・ファイルは以下のようにして列挙できる:
$ find $HOME/work/dotty -name '*.scala' -type f -exec wc -l {} + | sort -rn | head -n 10
250913 total
223621 total
7122 ~/work/dotty/tests/run/bridges.scala
5835 ~/work/dotty/compiler/src/dotty/tools/dotc/core/Types.scala
4313 ~/work/dotty/compiler/src/dotty/tools/backend/sjs/JSCodeGen.scala
4196 ~/work/dotty/library/src/scala/quoted/Quotes.scala
3971 ~/work/dotty/compiler/src/dotty/tools/dotc/parsing/Parsers.scala
3748 ~/work/dotty/compiler/src/dotty/tools/dotc/typer/Typer.scala
3002 ~/work/dotty/tests/disabled/reflect/run/t7556/mega-class_1.scala
2886 ~/work/dotty/compiler/src/scala/quoted/runtime/impl/QuotesImpl.scala
$ scalac --version
Scala compiler version 3.2.1 -- Copyright 2002-2022, LAMP/EPFL
$ time scalac $HOME/work/dotty/compiler/src/dotty/tools/dotc/core/Types.scala -Ystop-after:parser -Ylog:parser -d /tmp/target/
scalac $HOME/work/dotty/compiler/src/dotty/tools/dotc/core/Types.scala -d 4.02s user 0.31s system 219% cpu 1.980 total
$ time tree-sitter parse $HOME/work/dotty/compiler/src/dotty/tools/dotc/core/Types.scala -q
/Users/xxx/work/dotty/compiler/src/dotty/tools/dotc/core/Types.scala 60 ms (ERROR [111, 22] - [111, 27])
tree-sitter parse -q 0.07s user 0.00s system 96% cpu 0.073 total
$ time scalac $HOME/work/dotty/compiler/src/dotty/tools/dotc/parsing/Parsers.scala -Ystop-after:parser -Ylog:parser -d /tmp/target/
scalac $HOME/work/dotty/compiler/src/dotty/tools/dotc/parsing/Parsers.scala 3.54s user 0.29s system 206% cpu 1.854 total
$ time tree-sitter parse $HOME/work/dotty/compiler/src/dotty/tools/dotc/parsing/Parsers.scala -q
/Users/xxx/work/dotty/compiler/src/dotty/tools/dotc/parsing/Parsers.scala 26 ms (ERROR [49, 4] - [49, 8])
tree-sitter parse -q 0.03s user 0.00s system 91% cpu 0.040 total
compiler/src/dotty/tools/dotc/typer/ErrorReporting.scala みたいな数百行ぐらいのコードだと tree-sitter は1桁台ミリ秒を自分で報告している:
$ time scalac $HOME/work/dotty/compiler/src/dotty/tools/dotc/typer/ErrorReporting.scala -Ystop-after:parser -Ylog:parser -d /tmp/target/
scalac -Ystop-after:parser -Ylog:parser -d /tmp/target/ 2.88s user 0.27s system 182% cpu 1.736 total
$ time tree-sitter parse $HOME/work/dotty/compiler/src/dotty/tools/dotc/typer/ErrorReporting.scala -q
/Users/xxx/work/dotty/compiler/src/dotty/tools/dotc/typer/ErrorReporting.scala 5 ms (ERROR [22, 61] - [22, 66])
tree-sitter parse -q 0.01s user 0.00s system 85% cpu 0.013 total
| source | lines | Dotty | tree-sitter | speedup |
|---|---|---|---|---|
Types.scala |
5835 |
1980ms |
73ms |
27x |
Parsers.scala |
3971 |
1854ms |
40ms |
46x |
ErrorReporting.scala |
361 |
1736ms |
13ms |
134x |
Tree-sitter の絶対値としての速さを置いておいても、5474行を追加したとき Dotty は 244ms 追加でかかるが、Tree-sitter は 60ms しか増えていないことに注目してほしい。
これは Dotty が約 20 sloc/ms でパースするのに対して、Tree-sitter は 91 sloc/ms でパースしていることを示す。
文法が Scala 3 構文を網羅していないためこれらのパース結果は部分的エラーを含んでいるが、僕の予想だとパース速度的にはだから得をしているということは無いと思う。
まとめ
- Tree-sitter は、C言語を対象とした汎用パーサ生成器で、ソースコードの高速、差分、かつ部分的エラーを許容する堅牢なパースを可能とする。
- 当初 Atom で採用され、今後 Neovim が構文ハイライトや畳み込みなど豊かな言語機能を提供するのに採用予定だ。Emacs 29 も採用予定。
- 現在 Scala で使う場合の課題は tree-sitter/tree-sitter-scala が Scala 3 の新構文に対応していなことで、それを ‘Optional braces, part 2’ (#62) その他のプルリクが改善することを目指している。
- Neovim を設定して eed3si9n/tree-sitter-scala#fork-integration ブランチを使うことが可能。
関連リンク
Tree-sitter が Scala 3 構文に対応して無いことは他の人たちも以前に話題にあげている:
- 2021年5月 Scala Users フォーラムで Graham Brown さんが Scala 3 Syntax Highlighting in vim という質問を書いた。
- 2021年11月に ‘Scala 3 syntax support?’ #43 という Github issue が立てられ、41 like がついたが、今の所メンテナからのコメントは無し。
- 2021年11月に Chris Kipp さんが Scala Contributors フォーラムにて ‘Scala 3 syntax support in “other” editors’ を立てた。