sbt 2.x remote cache with Bazel compatibility
This is part 3 of the sbt 2.x remote cache series. I’ve have been developing sbt 2.x for a few years in my own free time, and lately Scala Center is joining the effort. These posts are extended PR descriptions to share the features that will come to the future version of sbt, hopefully.
About a year ago I proposed a design for automatic cached task for sbt 2.x in RFC-1: sbt cache ideas, and in the sbt 2.x remote cache post I implemented and dug into the details of caching:
someKey := Def.cachedTask {
val output = StringVirtualFile1("a.txt", "foo")
Def.declareOutput(output)
name.value + version.value + "!"
}
A remote cache, or a cloud build system, can speed up builds dramatically by sharing build results cross machines. In 2020, I implemented cached compilation in sbt 1.x. While this feature works only for compile, there’s been reports of significant performance improvements using it. Most recently, in Leveraging sbt remote caching on a big modular monolith (2024), Sébastien Boulet at Teads reported:
In case of a full cache hit, the sbt build takes about 3min 30 seconds. This duration is still a few minutes because not all sbt tasks are cached. … On the other hand, when there is a full cache miss, for example when Scala Steward opens a pull request to bump a library, everything is rebuilt and all the tests are executed. That takes up to 45 minutes. Therefore, a fully cached build is more than 92% efficient.
In real life, what engineers experience often falls somewhere between these two extremes. Build times can vary significantly based on the changes they make.
Back in sbt 2.x cache, thus far I’ve mostly focused on retrofitting the foundation for a generic mechanism using compile tasks, and I have not gotten around to implementing the remote part of the remote cache. We’ll take a look at it in this post.
The implementation proposal is at sbt/sbt#7525.
Bazel and its remote cache
Bazel is an open-source build tool, like Make or sbt. A major aspect of Bazel is that it’s designed around reproducibility and caching. Bazel supports both disk cache and remote cache, and the protocol the remote cache uses is publicly available as the Remote Execution API via gRPC, in addition to plain HTTP. There are currently 11 implementations of the remote cach backends, both open source and proprietary known publicly (I’ve personally worked on a few private ones); and analogous to Language Server Protocol, build tools other than Bazel like Buck2 are starting to support this API. As the name suggests, the API supports remote execution, but we’ll just use the caching end points.
To clarify, I am not suggesting that we limit sbt’s remote cache backends only to be Bazel remote caches. Instead, what I am proposing is to make sure we capture necessary information such that if we wanted to, sbt can talk to Bazel remote caches as if it is Bazel. Let’s call this property Bazel-compat. Additionally, if people wanted to extend it to support S3 etc they should be able to do so by implementing 6 or so methods.
One benefit of staying Bazel-compat is that we would be following battle-tested ideas like tracking the SHA-256 of task inputs as well as the SHA-256 (or SHA-512 in the future if necessary) of the outputs and their file size.
a cascadate of cacheStores
sbt 2.x adds a new setting called cacheStores. The decision tree looks like the following diagram:
┌────────────┐ yes? ┌─────┐
│ Disk Cache ├──────►│ JAR │
└─┬──────────┘ └───▲─┘
│ no │
┌───▼──────────┐ yes? ┌───┴─────────┐
│ Remote Cache ├──────►│ Download to │
└───┬──────────┘ │ Disk Cache │
│ no └─────────────┘
│
┌───▼──────────┐ ┌───────────────┐
│ Onsite Task ├──────►│ Upload to │
└──────────────┘ │ Remote Cache/ │
│ Copy to │
│ Disk Cache │
└───────────────┘
For cacheable tasks, sbt will try the cache stores in order, and use the JAR etc when they are available in cache. First, it will try the disk cache, and if there’s a JAR file, sbt will use it. Next, it will try the remote cache. When the action cache is not available, sbt will run the task onsite and call put(...) to copy/upload the digest and outputs.
testing with Bazel remote cache implemetations
While there’s one Remote Execution API, in practice there are subtle details (bugs in my code) I found by trying different backends, requiring small fixes along the way. In the following, we’ll look into four Bazel remote cache backends.
gRPC authentication
There are a few flavors of gRPC authentication, and Bazel remote cache backends use various kind of them:
- Unauthenticated. Useful for testing.
- Default TLS/SSL.
- TLS/SSL with custom server certificate.
- TTL/SSL with custom server and client certificate, mTLS.
- Default TLS/SSL with API token header.
buchgr/bazel-remote
buchgr/bazel-remote was the first open-source remote cache that came to mind, so it felt like the first thing to try. You can grab the code from buchgr/bazel-remote and run it on a laptop using bazel:
bazel run :bazel-remote -- --max_size 5 --dir $HOME/work/bazel-remote/temp \
--http_address localhost:8000 \
--grpc_address localhost:2024
This should output something like:
$ bazel run :bazel-remote -- --max_size 5 --dir $HOME/work/bazel-remote/temp \
--http_address localhost:8000 \
--grpc_address localhost:2024
....
2024/03/31 01:00:00 Starting gRPC server on address localhost:2024
2024/03/31 01:00:00 HTTP AC validation: enabled
2024/03/31 01:00:00 Starting HTTP server on address localhost:8000
To configure sbt 2.x, add the following to project/plugins.sbt
addRemoteCachePlugin
and append the following to build.sbt:
Global / remoteCache := Some(uri("grpc://localhost:2024"))
Start an sbt shell:
$ sbt
sbt:remote-cache-example> compile
This will print something like this:
sbt:remote-cache-example> compile
[info] compiling 1 Scala source to target/out/jvm/scala-3.3.0/remote-cache-example/classes ...
[success] elapsed time: 3 s, cache 0%, 1 onsite task
sbt:remote-cache-example> exit
On the buchgr/bazel-remote terminal you should see something like:
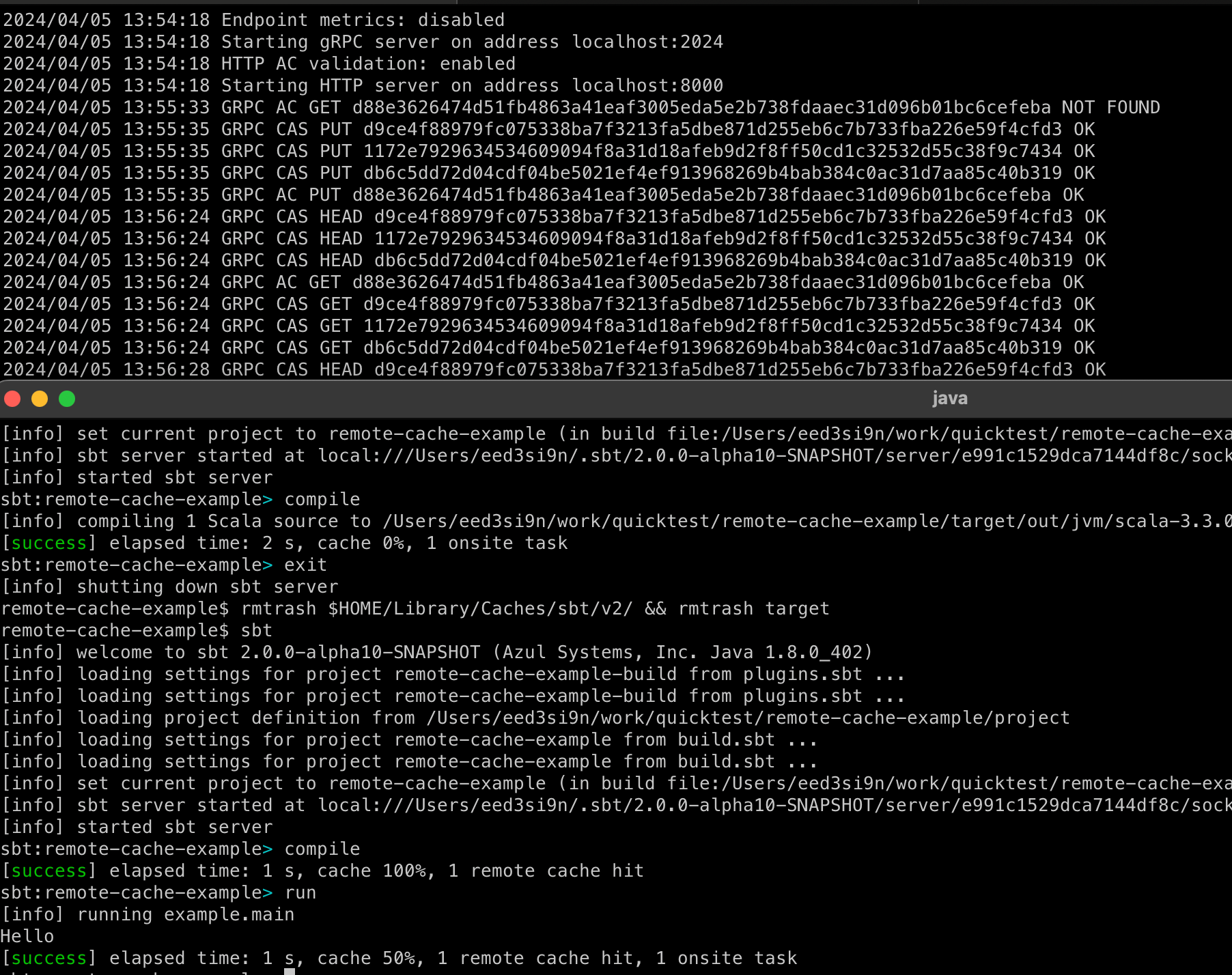
2024/03/31 01:00:00 GRPC AC GET d88e3626474d51fb4863a41eaf3005eda5e2b738fdaaec31d096b01bc6cefeba NOT FOUND
2024/03/31 01:00:00 GRPC CAS HEAD db6c5dd72d04cdf04be5021ef4ef913968269b4bab384c0ac31d7aa85c40b319 OK
2024/03/31 01:00:00 GRPC CAS PUT d9ce4f88979fc075338ba7f3213fa5dbe871d255eb6c7b733fba226e59f4cfd3 OK
2024/03/31 01:00:00 GRPC CAS PUT c4d4c1119e10b16b5af9b078b7d83c2cd91b0ba61979a6af57bf2f39ae649c11 OK
2024/03/31 01:00:00 GRPC AC PUT d88e3626474d51fb4863a41eaf3005eda5e2b738fdaaec31d096b01bc6cefeba O
This shows that sbt tried to query the AC (action cache) for d88e36, and got a cache miss, so sbt executed the task onsite organically. Then it uploaded two blobs as the result and updated the AC d88e36.
Next, let’s try again after wiping out the disk cache and local target directory. If remote cache works, we should be able to download the JAR instead running the task:
$ rmtrash $HOME/Library/Caches/sbt/v2/ && rmtrash target
$ sbt
sbt:remote-cache-example> compile
This time you should get:
sbt:remote-cache-example> compile
[success] elapsed time: 1 s, cache 100%, 1 remote cache hit
sbt:remote-cache-example> run
[info] running example.main
Hello
[success] elapsed time: 1 s, cache 50%, 1 remote cache hit, 1 onsite task
This shows we were able to pull a JAR from a Bazel remote cache, and run it. It worked!
configuring mTLS
In a real environment, mTLS can ensure that the transport is encrypted and mutually authenticated. buchgr/bazel-remote can be started with something like the follows:
bazel run :bazel-remote -- --max_size 5 --dir $HOME/work/bazel-remote/temp \
--http_address localhost:8000 \
--grpc_address localhost:2024 \
--tls_ca_file /tmp/sslcert/ca.crt \
--tls_cert_file /tmp/sslcert/server.crt \
--tls_key_file /tmp/sslcert/server.pem
sbt 2.x setting would look like this in this scenario:
Global / remoteCache := Some(uri("grpcs://localhost:2024"))
Global / remoteCacheTlsCertificate := Some(file("/tmp/sslcert/ca.crt"))
Global / remoteCacheTlsClientCertificate := Some(file("/tmp/sslcert/client.crt"))
Global / remoteCacheTlsClientKey := Some(file("/tmp/sslcert/client.pem"))
Note the grpcs://, as opposed to grpc://.
EngFlow
EngFlow GmbH is a build solution company founded in 2020 by core members of Bazel team, and it offers commercial service for build analytics and remote execution. Since sbt 2.x doesn’t produce the Build Event Protocol (BEP) data, we would only be using the remote caching part of EngFlow.
After signing up for trial on https://my.engflow.com/, the page instructs you to start a trial cluster using a docker.
docker run \
--env CLUSTER_UUID=.... \
--env UI_URL=http://localhost:8080 \
--env DATA_DIR=/usr/share/myengflow_mini \
--publish 8080:8080 \
--pull always \
--rm \
--volume ~/.cache/myengflow_mini:/usr/share/myengflow_mini \
ghcr.io/engflow/myengflow_mini
If you followed the instruction, this should start a remote cache service on port 8080. The sbt 2.x configuration would look like this for the trial cluster:
Global / remoteCache := Some(uri("grpc://localhost:8080"))
Run the following twice:
$ rmtrash $HOME/Library/Caches/sbt/v2/ && rmtrash target
$ sbt
sbt:remote-cache-example> compile
and you should get:
sbt:remote-cache-example> compile
[success] elapsed time: 1 s, cache 100%, 1 remote cache hit
BuildBuddy
BuildBuddy is a build solution company also founded by ex-Google engineers, providing build analytics and remote execution backend for Bazel. It’s also available open source as buildbuddy-io/buildbuddy.
After signing up, BuildBuddy Personal plan lets you use BuildBuddy cross the Internet.
- From https://app.buildbuddy.io/, go to Settings, and change the Organization URL to
<something>.buildbuddy.io. - Next, go to Quickstart and take note of the URLs and
--remote_headers. - Create a file called
$HOME/.sbt/buildbuddy_credential.txtand put in the API key:
x-buildbuddy-api-key=*******
The sbt 2.x configuration would look like this:
Global / remoteCache := Some(uri("grpcs://something.buildbuddy.io"))
Global / remoteCacheHeaders += IO.read(BuildPaths.defaultGlobalBase / "buildbuddy_credential.txt").trim
Run the following twice:
$ rmtrash $HOME/Library/Caches/sbt/v2/ && rmtrash target
$ sbt
sbt:remote-cache-example> compile
and you should get:
sbt:remote-cache-example> compile
[success] elapsed time: 1 s, cache 100%, 1 remote cache hit
NativeLink
NativeLink is a relatively new open-source Bazel remote execution backend implementated in Rust with emphasis on performance.
Update: As of June 2024, there’s NativeLink Cloud in beta.
- From https://app.nativelink.com/, go to Quickstart and take note of the URLs and
--remote_header. - Create a file called
$HOME/.sbt/nativelink_credential.txtand put in the API key:
x-nativelink-api-key=*******
The sbt 2.x configuration would look like this:
Global / remoteCache := Some(uri("grpcs://something.build-faster.nativelink.net"))
Global / remoteCacheHeaders += IO.read(BuildPaths.defaultGlobalBase / "nativelink_credential.txt").trim
Run the following twice:
$ rmtrash $HOME/Library/Caches/sbt/v2/ && rmtrash target
$ sbt
sbt:remote-cache-example> compile
and you should get:
sbt:remote-cache-example> compile
[success] elapsed time: 1 s, cache 100%, 1 remote cache hit
honorable mentions
- Buildfarm is an open-source Bazel remote execution that’s been around since 2017.
- Buildbarn is an open-source Bazel remote execution, also been around for a while. I haven’t tried it yet.
technical details
In the rest of the post, I’ll cover some technical details I came across while implementing the remote cache feature.
gRPC
gRPC is an open-source framework for remote procedure calls (RPC), originally developed at Google. I think of it as a modern incarnate of SOAP, in a sense that you define the wire protocol first, and multiple languages can generate stubs that can talk to each other using the said protocol. The Remote Execution API is a great example how of one protocol can be implemented by Scala, Go, Rust, etc. and talk with each other in binary. All the while, when you’re coding, there’s zero parsing because the stub defines function calls. Another great thing about gRPC is its ability to evolve the API over time since it uses Protocol Buffer.
I forked the remote-apis, added an sbt build to generate a Java stub, shaded all the dependencies, and published it on Maven Central as com.eed3si9n.remoteapis.shaded:shaded-remoteapis-java.
Contraband
Inside the sbt codebase, we’ve been using a similar idea to Protobuf called Contraband, which is an interface language to describe datatypes. In addition to the automatic JSON bindings, in Scala, Contraband generates a pseudo case class that’s capable of binary-compatible evolution.
For example, the following is ActionResult, which is based on the data structure of the same name in Remote Execution API, but some types changed to suit our internals:
package sbt.util
@target(Scala)
@codecPackage("sbt.internal.util.codec")
@fullCodec("ActionResultCodec")
## An ActionResult represents a result from executing a task.
## In addition to the value typically represented in the return type
## of a task, ActionResult tracks the file output and other side effects.
type ActionResult {
outputFiles: [xsbti.HashedVirtualFileRef] @since("0.1.0")
origin: String @since("0.2.0")
exitCode: Int @since("0.3.0")
contents: [java.nio.ByteBuffer] @since("0.4.0")
isExecutable: [Boolean] @since("0.5.0")
}
Contraband automatically derives sjsonnew.JsonFormat codec, and using that we can calculate the SHA-256 (See sbt 2.x remote cache for more details).
ActionCacheStore changes
The remote cache backends, including the local disk storage, is abstracted using the following trait (likely needs some more tweaks) with just 6 methods:
/**
* An abstration of a remote or local cache store.
*/
trait ActionCacheStore:
/**
* A named used to identify the cache store.
*/
def storeName: String
/**
* Put a value and blobs to the cache store for later retrieval,
* based on the `actionDigest`.
*/
def put(request: UpdateActionResultRequest): Either[Throwable, ActionResult]
/**
* Get the value for the key from the cache store.
* `inlineContentPaths` - paths whose contents would be inlined.
*/
def get(request: GetActionResultRequest): Either[Throwable, ActionResult]
/**
* Put VirtualFile blobs to the cache store for later retrieval.
*/
def putBlobs(blobs: Seq[VirtualFile]): Seq[HashedVirtualFileRef]
/**
* Materialize blobs to the output directory.
*/
def syncBlobs(refs: Seq[HashedVirtualFileRef], outputDirectory: Path): Seq[Path]
/**
* Find if blobs are present in the storage.
*/
def findBlobs(refs: Seq[HashedVirtualFileRef]): Seq[HashedVirtualFileRef]
end ActionCacheStore
When I implemented Def.cachedTask in December, I did read the API, but implemented it partly based on my own imagination, like ActionResult[A1] always holding a value of type A1. Once I started implementing gRPC client, I realized that the API is even simpler. Any contents are tracked in CAS (content addressable storage), and ActionResult holds on to a list of outputs files. This means that ActionResult shouldn’t be parameterized by a type parameter. I was partly right in that get(...) call can request some outputs to be inlined into the response. So if we encode task result as JSON, we can ask the remote cache to send it in ActionResult as a payload, instead of separate syncBlobs(...), saving one network roundtrip.
Digest changes
Another thing that I didn’t catch in December was Digest.
A content digest. A digest for a given blob consists of
the size of the blob and its hash.
The hash algorithm to use is defined by the server.
The size is considered to be an integral part of the
digest and cannot be separated. That is, even if the
`hash` field is correctly specified but
`size_bytes` is not, the server MUST reject the request.
The comment in the API clearly states that the size_bytes is meant to represent the file size, but I had overlooked this to be part of the digest calculation.
For a while I kept sending the size of the digest in bytes, and kept missing the cache.
Once I fixed the digest, I was able to retrieve the blobs from cache.
the plugin approach
Since the com.eed3si9n.remoteapis.shaded:shaded-remoteapis-java is 11MB, I implemented the Bazel-compat to be a plugin. This way people can decide if they want to opt into using this feature.
next steps: fallbacks?
While I gush over Bazel, I actually don’t think it’s a perfect system. I listed a list of potential caching pitfalls in the previous post. Specifically package aggregation issue is important:
The gist of the issue is that the more source files you aggregate into a subproject, the more inter-connected the subprojects become, and naïve invalidation of simply inverting the dependency graph would end up spreading the initial invalidation (code changes) to most of the monorepo like a wildfire.
While Bazel employs small packages and strict deps to counter the package aggregation, sbt can do a better job at managing invalidation since we operate at language level via Zinc. For example, just because B.scala uses A.scala and A.scala was changed, Zinc won’t invalidate B.scala unless the signature of the entity used by B.scala changed.
With sbt 1.x cached compilation (2020), I’ve provided a way to resume incremental compilation from a difference machine by pulling Zinc Analysis file from a previous git commit. If we assume that main branch would most likely be well-cached, it might be worth implementing similar to sbt 2.x as well.
next steps: testQuick by default
sbt 1.x already implements incremental testing called testQuick, but I don’t know if it’s well-known. Assuming most CI process just calls test, I think it would be good to cache the test results and make testQuick the default behavior like Bazel.
To rerun the test, Bazel require a flag:
bazel test --cache_test_results=no <query>
One of the secrets of Bazel speed is skipping all the unchanged tests.
summary
Building upon RFC-1: sbt cache ideas, Def.cachedTask, and Bazel’s Remote Execution API, sbt/sbt#7525 implements remote cache client feature for sbt 2.x. We’ve shown that sbt 2.x remote cache can populate and retrieve task results from a number of implementations:
- buchgr/bazel-remote
- EngFlow
- BuildBuddy
- NativeLink
- and many more
Remote caching gives us a new degree of build scalability, that can scale linearly with the team size, as opposed to everyone building everyone else’s changes all the time. Even for small projects, being able to share the binary outputs among the contributors makes the development more efficient. This is analogous to Maven Central sharing JARs, except without constantly bumping version numbers and hopefully for more tasks other than compile.
There are more challenges lie ahead in terms of the remote cache support overall, but Bazel-compat is a big milestone for me.
Donate to Scala Center
Scala Center is a non-profit center at EPFL to support education and open source. Please consider donating to them, and publicly tweet/toot at @eed3si9n and @scala_lang when you do (I don’t work for them, but we maintain sbt together).